PENGANTAR KOMPUTASI PARAREL
Abstrak
Ini adalah tutorial pertama dalam lokakarya "Memulai Komputasi Livermore". Ini dimaksudkan untuk memberikan hanya gambaran singkat tentang topik Komputasi Paralel yang luas dan luas, sebagai panduan untuk tutorial yang mengikutinya. Dengan demikian, ini hanya mencakup dasar-dasar komputasi paralel, dan ditujukan untuk seseorang yang baru mengenal subjek tersebut dan yang berencana untuk menghadiri satu atau lebih tutorial lain dalam lokakarya ini. Ini tidak dimaksudkan untuk membahas Pemrograman Paralel secara mendalam, karena ini akan membutuhkan lebih banyak waktu secara signifikan. Tutorial dimulai dengan diskusi tentang komputasi paralel - apa itu komputasi paralel dan bagaimana penggunaannya, diikuti dengan diskusi tentang konsep dan terminologi yang terkait dengan komputasi paralel. Topik arsitektur memori paralel dan model pemrograman kemudian dieksplorasi. Topik-topik ini diikuti dengan serangkaian diskusi praktis tentang sejumlah masalah kompleks yang terkait dengan perancangan dan menjalankan program paralel. Tutorial diakhiri dengan beberapa contoh bagaimana memparalelkan program serial sederhana. Referensi disertakan untuk studi mandiri lebih lanjut.
Gambaran
Apa itu Komputasi Paralel?
Komputasi Serial
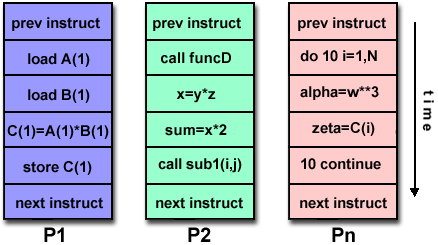
Secara tradisional, perangkat lunak telah ditulis untuk komputasi serial :
- Masalah dipecah menjadi serangkaian instruksi terpisah
- Instruksi dijalankan secara berurutan satu demi satu
- Dieksekusi pada satu prosesor
- Hanya satu instruksi yang dapat dijalankan setiap saat
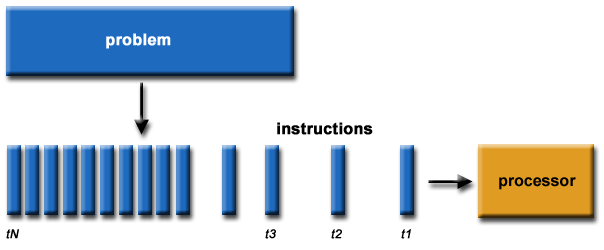
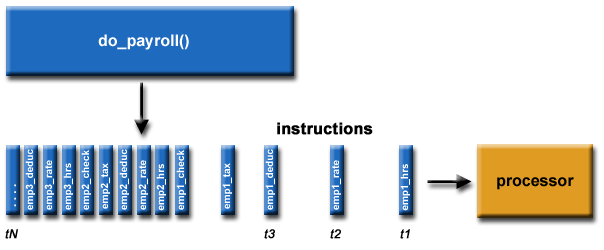
Sebagai contoh:
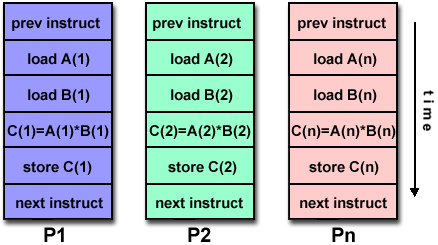
Komputasi Paralel
Dalam arti yang paling sederhana, komputasi paralel adalah penggunaan beberapa sumber daya komputasi secara bersamaan untuk memecahkan masalah komputasi:
- Masalah dipecah menjadi beberapa bagian yang dapat diselesaikan secara bersamaan
- Setiap bagian selanjutnya dipecah menjadi serangkaian instruksi
- Instruksi dari setiap bagian dijalankan secara bersamaan pada prosesor yang berbeda
- Mekanisme kontrol / koordinasi keseluruhan digunakan
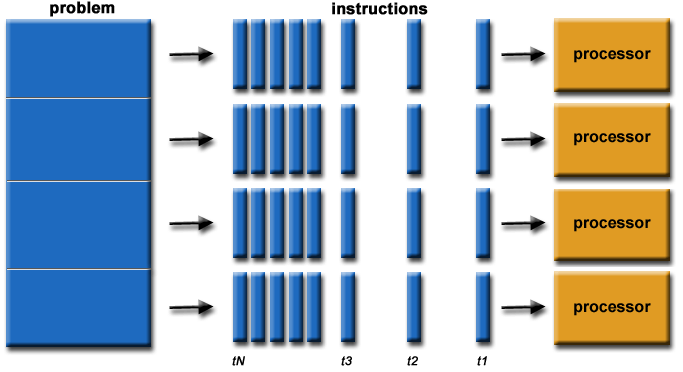
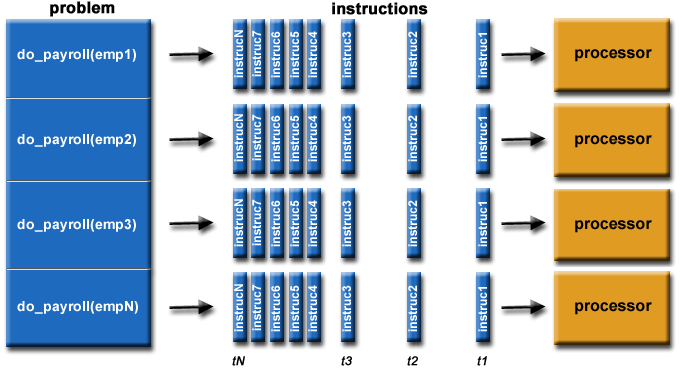
Sebagai contoh:
- Masalah komputasi harus mampu:
- Dipecah menjadi beberapa bagian pekerjaan yang dapat diselesaikan secara bersamaan;
- Jalankan beberapa instruksi program kapan saja;
- Dipecahkan dalam waktu yang lebih singkat dengan beberapa sumber daya komputasi dibandingkan dengan satu sumber daya komputasi.
- Sumber daya komputasi biasanya:
- Satu komputer dengan banyak prosesor / inti
- Sejumlah sembarang komputer yang terhubung oleh jaringan
Komputer Paralel
- Hampir semua komputer yang berdiri sendiri saat ini paralel dari perspektif perangkat keras:
- Beberapa unit fungsional (cache L1, cache L2, cabang, prefetch, decode, floating-point, pemrosesan grafis (GPU), integer, dll.)
- Beberapa unit / inti eksekusi
- Beberapa utas perangkat keras
 dan 16 unit L2 Cache (L2)")
IBM BG / Q Compute Chip dengan 18 core (PU) dan 16 unit L2 Cache (L2)
- Jaringan menghubungkan beberapa komputer yang berdiri sendiri (node) untuk membuat cluster komputer paralel yang lebih besar.
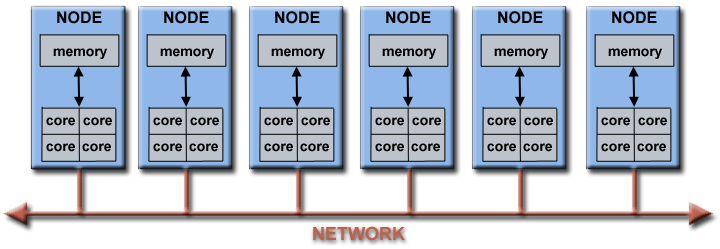
- Misalnya, skema di bawah ini menunjukkan cluster komputer paralel LLNL yang khas:
- Setiap node komputasi adalah komputer paralel multi-prosesor itu sendiri
- Beberapa node komputasi terhubung ke jaringan bersama dengan jaringan Infiniband
- Node tujuan khusus, juga multi-prosesor, digunakan untuk tujuan lain
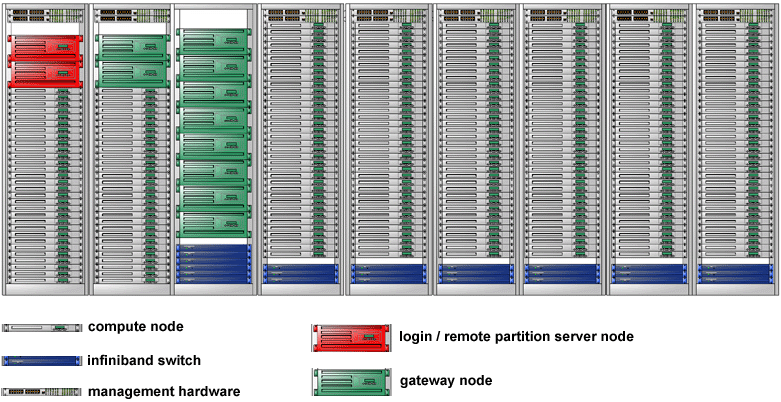
- Mayoritas komputer paralel besar di dunia (superkomputer) adalah kumpulan perangkat keras yang diproduksi oleh segelintir (kebanyakan) vendor terkenal.
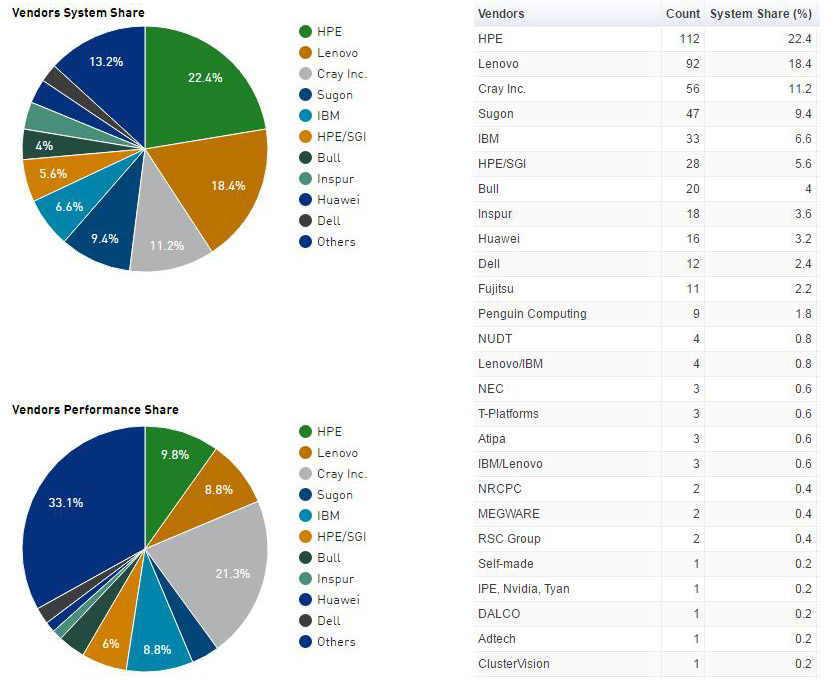
Sumber: Top500.org
Mengapa Menggunakan Komputasi Paralel?
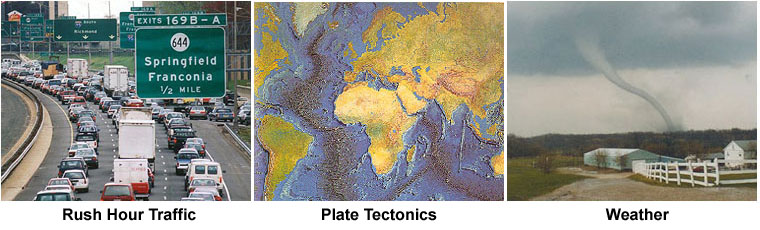
Dunia Nyata Sangat Paralel
- Di alam, banyak peristiwa kompleks dan saling terkait terjadi pada waktu yang sama, namun dalam urutan temporal.
- Dibandingkan dengan komputasi serial, komputasi paralel jauh lebih cocok untuk pemodelan, simulasi, dan pemahaman fenomena dunia nyata yang kompleks.
- Misalnya, bayangkan memodelkan ini secara serial:

Alasan utama
HEMAT WAKTU DAN / ATAU UANG
- Secara teori, membuang lebih banyak sumber daya pada suatu tugas akan mempersingkat waktu penyelesaiannya, dengan potensi penghematan biaya.
- Komputer paralel dapat dibuat dari komponen komoditas yang murah.

MEMECAHKAN MASALAH YANG LEBIH BESAR / LEBIH KOMPLEKS
- Banyak masalah yang begitu besar dan / atau kompleks sehingga tidak praktis atau tidak mungkin diselesaikan dengan menggunakan program serial, terutama mengingat memori komputer yang terbatas.
- Contoh: "Masalah Tantangan Besar" ( en.wikipedia.org/wiki/Grand_Challenge ) yang membutuhkan sumber daya komputasi petaflops dan petabyte.
- Contoh: Mesin pencari / database web yang memproses jutaan transaksi setiap detik

MEMBERIKAN KONSURENSI
- Sumber daya komputasi tunggal hanya dapat melakukan satu hal dalam satu waktu. Berbagai sumber daya komputasi dapat melakukan banyak hal secara bersamaan.
- Contoh: Jaringan Kolaboratif menyediakan tempat global di mana orang-orang dari seluruh dunia dapat bertemu dan melakukan pekerjaan "secara virtual".
AMBIL KEUNTUNGAN DARI SUMBER DAYA NON-LOKAL
- Menggunakan sumber daya komputasi di jaringan area luas, atau bahkan Internet ketika sumber daya komputasi lokal langka atau tidak mencukupi.
- Contoh: SETI @ home( setiathome.berkeley.edu ) memiliki lebih dari 1,7 juta pengguna di hampir setiap negara di dunia. (Mei, 2018).
- Contoh: Lipat @ rumah( folding.stanford.edu ) lebih dari 1,8 juta kontributor di seluruh dunia (Mei, 2018)

LEBIH BAIK MENGGUNAKAN PERANGKAT KERAS PARALEL DASAR
- Komputer modern, bahkan laptop, memiliki arsitektur paralel dengan banyak prosesor / inti.
- Perangkat lunak paralel secara khusus ditujukan untuk perangkat keras paralel dengan banyak inti, utas, dll.
- Dalam kebanyakan kasus, program serial yang dijalankan pada komputer modern "membuang" daya komputasi potensial.

Masa depan
- Selama 20+ tahun terakhir, tren yang ditunjukkan oleh jaringan yang semakin cepat, sistem terdistribusi, dan arsitektur komputer multi-prosesor (bahkan di tingkat desktop) dengan jelas menunjukkan bahwa paralelisme adalah masa depan komputasi .
- Dalam periode waktu yang sama ini, telah terjadi peningkatan kinerja superkomputer lebih dari 500.000x , tanpa akhir yang terlihat saat ini.
- Perlombaan untuk Exascale Computing sudah dimulai!
- Exaflop = 10 18 perhitungan per detik
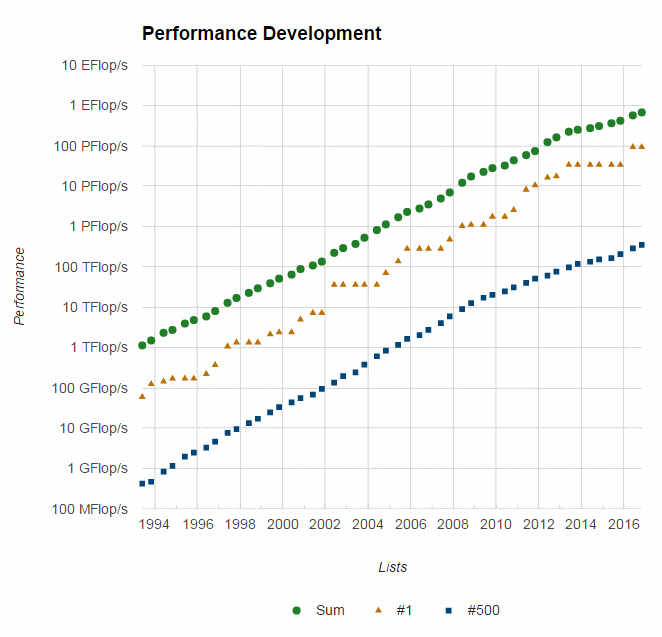
Sumber: Top500.org
Siapa yang Menggunakan Komputasi Paralel?
Sains dan Teknik
- Secara historis, komputasi paralel telah dianggap sebagai "komputasi kelas atas", dan telah digunakan untuk memodelkan masalah yang sulit di banyak bidang sains dan teknik:
- Atmosfer, Bumi, Lingkungan
- Fisika - terapan, nuklir, partikel, materi terkondensasi, tekanan tinggi, fusi, fotonik
- Biosains, Bioteknologi, Genetika
- Kimia, Ilmu Molekuler
- Geologi, Seismologi
- Teknik Mesin - dari prostetik hingga pesawat ruang angkasa
- Teknik Elektro, Desain Sirkuit, Mikroelektronika
- Ilmu Komputer, Matematika
- Pertahanan, Senjata

Industri dan Komersial
- Saat ini, aplikasi komersial memberikan kekuatan pendorong yang sama atau lebih besar dalam pengembangan komputer yang lebih cepat. Aplikasi ini membutuhkan pemrosesan data dalam jumlah besar dengan cara yang canggih. Sebagai contoh:
- "Big Data", database, penambangan data
- Kecerdasan Buatan (AI)
- Eksplorasi minyak
- Mesin pencari web, layanan bisnis berbasis web
- Pencitraan dan diagnosis medis
- Desain farmasi
- Pemodelan keuangan dan ekonomi
- Manajemen perusahaan nasional dan multinasional
- Grafik canggih dan virtual reality, khususnya di industri hiburan
- Video berjaringan dan teknologi multi-media
- Lingkungan kerja kolaboratif

Aplikasi Global
- Komputasi paralel sekarang digunakan secara luas di seluruh dunia, dalam berbagai macam aplikasi.
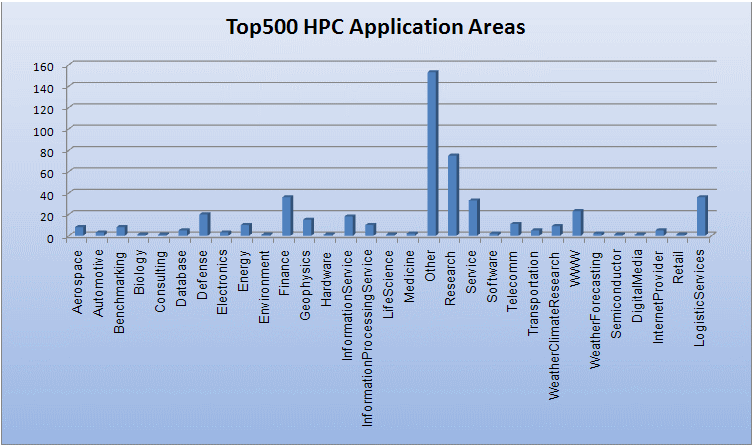
Sumber: Top500.org
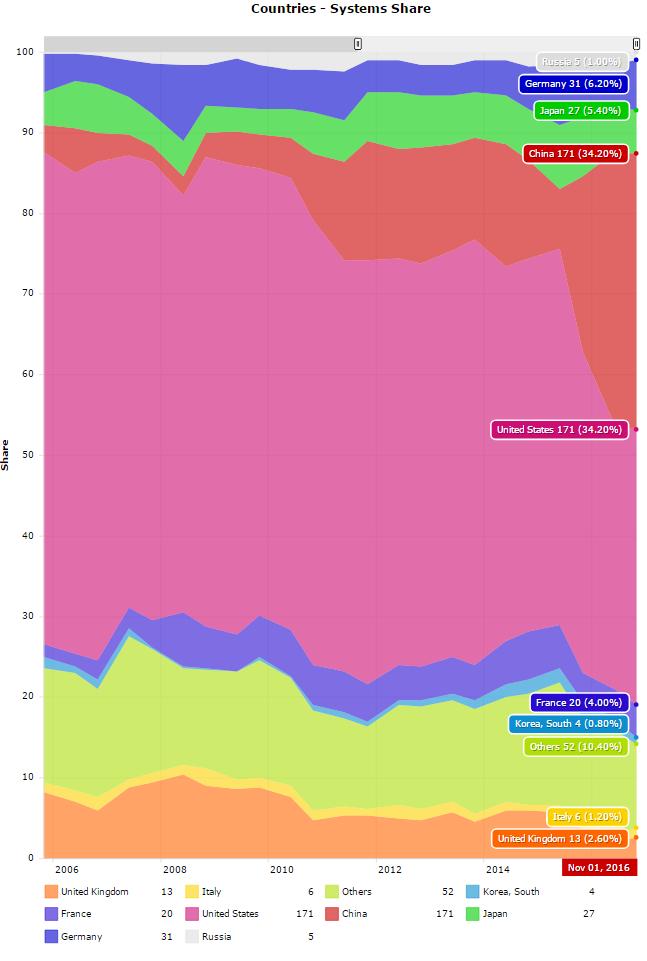
Konsep dan Terminologi
Arsitektur von Neumann

John von Neumann sekitar tahun 1940-an(Sumber: Arsip LANL)
- Dinamakan setelah matematikawan Hungaria John von Neumann yang pertama kali menulis persyaratan umum untuk komputer elektronik di tahun 1945 makalahnya.
- Juga dikenal sebagai "komputer program tersimpan" - baik instruksi program maupun data disimpan dalam memori elektronik. Berbeda dari komputer sebelumnya yang diprogram melalui "kabel keras".
- Sejak itu, hampir semua komputer mengikuti desain dasar ini:
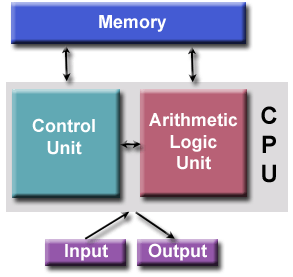
- Terdiri dari empat komponen utama:
- Baca / tulis, memori akses acak digunakan untuk menyimpan instruksi program dan data
<ol style = "list-style-type: lower-alpha;">
- Unit kontrol mengambil instruksi / data dari memori, menerjemahkan instruksi dan kemudian secara berurutan mengoordinasikan operasi untuk menyelesaikan tugas yang diprogram.
- Unit Aritmatika melakukan operasi aritmatika dasar
- Input / Output adalah antarmuka ke operator manusia
- Info lebih lanjut tentang pencapaian luar biasa lainnya: http://en.wikipedia.org/wiki/John_von_Neumann
- Terus? Siapa peduli?
- Nah, komputer paralel masih mengikuti desain dasar ini, hanya dikalikan dalam satuan. Arsitektur dasar dan fundamental tetap sama.
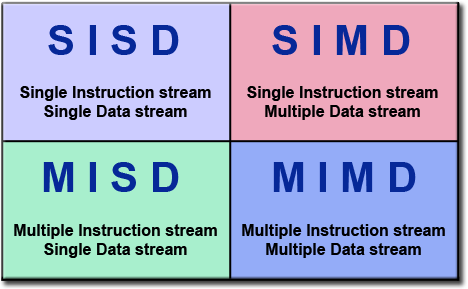
Taksonomi Klasik Flynn
- Ada beberapa cara berbeda untuk mengklasifikasikan komputer paralel. Contoh tersedia di referensi .
- Salah satu klasifikasi yang lebih banyak digunakan, digunakan sejak 1966, disebut Taksonomi Flynn.
- Taksonomi Flynn membedakan arsitektur komputer multi-prosesor menurut bagaimana mereka dapat diklasifikasikan sepanjang dua dimensi independen Arus Instruksi dan Aliran Data . Masing-masing dimensi ini hanya dapat memiliki satu dari dua kemungkinan status: Tunggal atau Banyak .
- Matriks di bawah ini mendefinisikan 4 kemungkinan klasifikasi menurut Flynn:
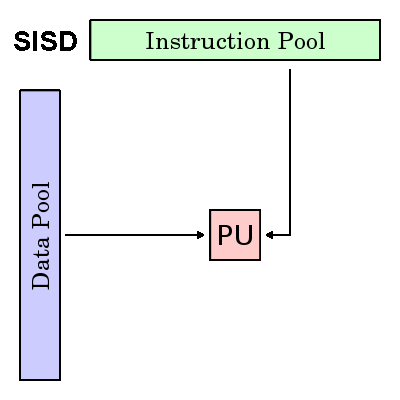
Instruksi Tunggal, Data Tunggal (SISD)
- Komputer serial (non-paralel)
- Instruksi Tunggal: Hanya satu aliran instruksi yang sedang ditindaklanjuti oleh CPU selama satu siklus clock
- Data Tunggal: Hanya satu aliran data yang digunakan sebagai input selama satu siklus jam
- Eksekusi deterministik
- Ini adalah jenis komputer tertua
- Contoh: mainframe generasi lama, minikomputer, workstation, dan prosesor / inti PC tunggal.
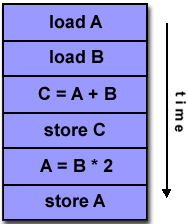






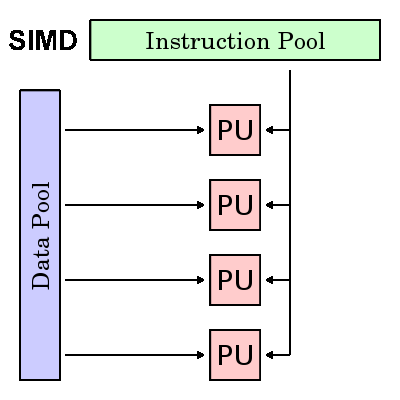
Instruksi Tunggal, Banyak Data (SIMD)
- Jenis komputer paralel
- Instruksi Tunggal: Semua unit pemrosesan menjalankan instruksi yang sama pada siklus jam tertentu
- Beberapa Data: Setiap unit pemrosesan dapat beroperasi pada elemen data yang berbeda
- Paling cocok untuk masalah khusus yang ditandai dengan tingkat keteraturan yang tinggi, seperti pemrosesan grafik / gambar.
- Eksekusi sinkron (langkah kunci) dan deterministik
- Dua jenis: Array Prosesor dan Pipa Vektor
- Contoh:
- Array Prosesor: Mesin Berpikir CM-2, MasPar MP-1 & MP-2, ILLIAC IV
- Pipa Vektor: IBM 9000, Cray X-MP, Y-MP & C90, Fujitsu VP, NEC SX-2, Hitachi S820, ETA10
- Sebagian besar komputer modern, terutama yang memiliki unit prosesor grafis (GPU) menggunakan instruksi SIMD dan unit eksekusi.






")
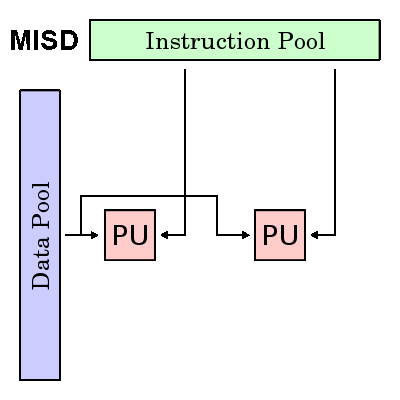
Beberapa Instruksi, Data Tunggal (MISD)
- Jenis komputer paralel
- Beberapa Instruksi: Setiap unit pemrosesan beroperasi pada data secara independen melalui aliran instruksi terpisah.
- Data Tunggal: Aliran data tunggal dimasukkan ke dalam beberapa unit pemrosesan.
- Beberapa (jika ada) contoh aktual dari kelas komputer paralel ini yang pernah ada.
- Beberapa kemungkinan penggunaan mungkin adalah:
- beberapa filter frekuensi yang beroperasi pada aliran sinyal tunggal
- beberapa algoritma kriptografi mencoba memecahkan pesan berkode tunggal.

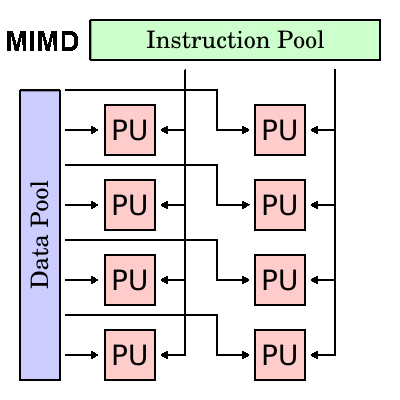
Banyak Instruksi, Banyak Data (MIMD)
- Jenis komputer paralel
- Multiple Instruction: Setiap prosesor mungkin menjalankan aliran instruksi yang berbeda
- Beberapa Data: Setiap prosesor mungkin bekerja dengan aliran data yang berbeda
- Eksekusi bisa sinkron atau asinkron, deterministik atau non-deterministik
- Saat ini, jenis komputer paralel yang paling umum - superkomputer paling modern termasuk dalam kategori ini.
- Contoh: superkomputer terkini, cluster komputer paralel berjaringan dan "grid", komputer SMP multi-prosesor, PC multi-core.
- Perhatikan bahwa banyak arsitektur MIMD juga menyertakan sub-komponen eksekusi SIMD






Beberapa Terminologi Paralel Umum
- Seperti yang lainnya, komputasi paralel memiliki "jargon" sendiri. Beberapa istilah yang lebih umum digunakan yang terkait dengan komputasi paralel tercantum di bawah ini.
- Sebagian besar akan dibahas lebih rinci nanti.
SUPERCOMPUTING / HIGH PERFORMANCE COMPUTING (HPC)
Menggunakan komputer tercepat dan terbesar di dunia untuk memecahkan masalah besar.
NODE
"Komputer dalam kotak" yang berdiri sendiri. Biasanya terdiri dari beberapa CPU / prosesor / inti, memori, antarmuka jaringan, dll. Node-node dihubungkan bersama untuk membentuk superkomputer.
CPU / SOKET / PROSESOR / INTI
Ini bervariasi, tergantung dengan siapa Anda berbicara. Di masa lalu, CPU (Central Processing Unit) adalah komponen eksekusi tunggal untuk komputer. Kemudian, beberapa CPU digabungkan ke dalam satu node. Kemudian, masing-masing CPU dibagi lagi menjadi beberapa "inti", masing-masing menjadi unit eksekusi yang unik. CPU dengan banyak inti kadang-kadang disebut "soket" - tergantung vendor. Hasilnya adalah node dengan banyak CPU, masing-masing berisi banyak inti. Nomenklaturnya terkadang membingungkan. Bertanya-tanya mengapa?

TUGAS
Bagian yang terpisah secara logis dari pekerjaan komputasi. Sebuah tugas biasanya merupakan program atau sekumpulan instruksi seperti program yang dijalankan oleh prosesor. Program paralel terdiri dari banyak tugas yang berjalan pada banyak prosesor.
PIPELINING
Memecah tugas menjadi langkah-langkah yang dilakukan oleh unit prosesor yang berbeda, dengan input mengalir melalui, seperti jalur perakitan; sejenis komputasi paralel.
BERBAGI MEMORI
Dari sudut pandang perangkat keras, menjelaskan arsitektur komputer di mana semua prosesor memiliki akses langsung (biasanya berbasis bus) ke memori fisik umum. Dalam pengertian pemrograman, ini menjelaskan model di mana tugas-tugas paralel semua memiliki "gambar" yang sama dari memori dan dapat langsung menangani dan mengakses lokasi memori logis yang sama terlepas dari di mana memori fisik sebenarnya ada.
MULTI-PROSESOR SIMETRIS (SMP)
Arsitektur perangkat keras memori bersama di mana beberapa prosesor berbagi ruang alamat tunggal dan memiliki akses yang sama ke semua sumber daya.
MEMORI TERDISTRIBUSI
Dalam perangkat keras, mengacu pada akses memori berbasis jaringan untuk memori fisik yang tidak umum. Sebagai model pemrograman, tugas hanya dapat secara logis "melihat" memori mesin lokal dan harus menggunakan komunikasi untuk mengakses memori pada mesin lain di mana tugas lain sedang dijalankan.
KOMUNIKASI
Tugas paralel biasanya perlu bertukar data. Ada beberapa cara yang dapat dilakukan, seperti melalui bus memori bersama atau melalui jaringan, namun peristiwa pertukaran data yang sebenarnya biasanya disebut sebagai komunikasi terlepas dari metode yang digunakan.
SINKRONISASI
Koordinasi tugas paralel dalam waktu nyata, sangat sering dikaitkan dengan komunikasi. Seringkali diimplementasikan dengan menetapkan titik sinkronisasi dalam aplikasi di mana tugas tidak dapat dilanjutkan hingga tugas lain mencapai titik yang sama atau secara logis setara.
Sinkronisasi biasanya melibatkan menunggu setidaknya satu tugas, dan oleh karena itu dapat menyebabkan waktu eksekusi jam dinding aplikasi paralel meningkat.
PERINCIAN
Dalam komputasi paralel, granularitas adalah ukuran kualitatif dari rasio komputasi terhadap komunikasi.
- Kasar: jumlah pekerjaan komputasi yang relatif besar dilakukan di antara peristiwa komunikasi
- Baik: sejumlah kecil pekerjaan komputasi dilakukan di antara peristiwa komunikasi
SPEEDUP TERAMATI
Percepatan yang diamati dari kode yang telah diparalelkan, didefinisikan sebagai:
waktu jam dinding dari eksekusi serial-----------------------------------waktu jam dinding dari eksekusi paralel
Salah satu indikator paling sederhana dan paling banyak digunakan untuk kinerja program paralel.
OVERHEAD PARALEL
Jumlah waktu yang diperlukan untuk mengoordinasikan tugas paralel, bukan untuk melakukan pekerjaan yang berguna. Overhead paralel dapat mencakup faktor-faktor seperti:
- Waktu mulai tugas
- Sinkronisasi
- Komunikasi data
- Overhead perangkat lunak yang dikenakan oleh bahasa paralel, perpustakaan, sistem operasi, dll.
- Waktu penghentian tugas
PARALEL BESAR-BESARAN
Mengacu pada perangkat keras yang terdiri dari sistem paralel tertentu - memiliki banyak elemen pemrosesan. Arti "banyak" terus meningkat, tetapi saat ini, komputer paralel terbesar terdiri dari elemen pemrosesan yang berjumlah ratusan ribu hingga jutaan.
PARALEL YANG MEMALUKAN
Memecahkan banyak tugas serupa, tetapi independen secara bersamaan; sedikit atau tidak perlu koordinasi antar tugas.
SKALABILITAS
Mengacu pada kemampuan sistem paralel (perangkat keras dan / atau perangkat lunak) untuk mendemonstrasikan peningkatan yang proporsional dalam percepatan paralel dengan penambahan lebih banyak sumber daya. Faktor-faktor yang berkontribusi pada skalabilitas meliputi:
- Perangkat keras - terutama bandwidth memori-cpu dan properti komunikasi jaringan
- Algoritma aplikasi
- Overhead paralel terkait
- Karakteristik aplikasi spesifik Anda
Batasan dan Biaya Pemrograman Paralel
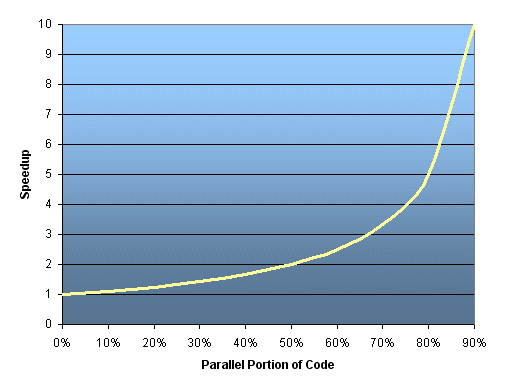
Hukum Amdahl
amdahl1.gif
amdahl2.gif
- Hukum Amdahl menyatakan bahwa percepatan program potensial ditentukan oleh pecahan kode (P) yang dapat diparalelkan:
1 percepatan = -------- 1 - P.
- Jika tidak ada kode yang dapat diparalelkan, P = 0 dan speedup = 1 (tidak ada speedup).
- Jika semua kode diparalelkan, P = 1 dan speedup tidak terbatas (dalam teori).
- Jika 50% kode bisa diparalelkan, speedup maksimum = 2, artinya kode akan berjalan dua kali lebih cepat.
- Memperkenalkan jumlah prosesor yang melakukan pekerjaan pecahan paralel, hubungan dapat dimodelkan dengan:
1 percepatan = ------------ P + S --- N
- dimana P = pecahan paralel, N = jumlah prosesor dan S = pecahan serial.
- Segera menjadi jelas bahwa ada batasan skalabilitas paralelisme. Sebagai contoh:
mempercepat ------------------------------------- NP = .50 P = .90 P = .95 P = 0,99 ----- ------- ------- ------- ------- 10 1,82 5,26 6,89 9,17 100 1,98 9,17 16,80 50,25 1.000 1,99 9,91 19,62 90,99 10.000 1,99 9,91 19,96 99,02 100.000 1,99 9,99 19,99 99,90
- Kutipan "Terkenal": Anda dapat menghabiskan waktu seumur hidup untuk membuat 95% kode Anda menjadi paralel, dan tidak pernah mencapai kecepatan yang lebih baik dari 20x tidak peduli berapa banyak prosesor yang Anda gunakan!
- Namun, masalah tertentu menunjukkan peningkatan kinerja dengan meningkatkan ukuran masalah. Sebagai contoh:
Perhitungan Grid 2D Fraksi paralel 85 detik 85% Fraksi serial 15 detik 15%
- Kita dapat meningkatkan ukuran masalah dengan menggandakan dimensi bingkai dan membagi setengah langkah waktu. Ini menghasilkan empat kali jumlah titik kisi dan dua kali jumlah langkah waktu. Pengaturan waktu akan terlihat seperti:
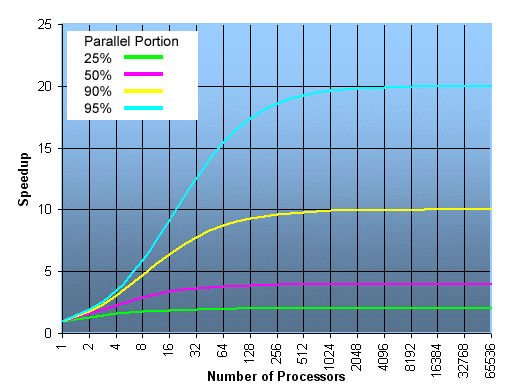
Perhitungan Grid 2DFraksi paralel 680 detik 97,84%Fraksi serial 15 detik 2,16%
- Masalah yang meningkatkan persentase waktu paralel dengan ukurannya lebih dapat diskalakan daripada masalah dengan persentase waktu paralel yang tetap.
Kompleksitas
- Secara umum, aplikasi paralel jauh lebih kompleks daripada aplikasi serial terkait, mungkin urutan besarnya. Anda tidak hanya memiliki beberapa aliran instruksi yang dijalankan pada saat yang sama, tetapi Anda juga memiliki data yang mengalir di antaranya.
- Biaya kompleksitas diukur dalam waktu programmer di hampir setiap aspek siklus pengembangan perangkat lunak:
- Rancangan
- Pengodean
- Debugging
- Tuning
- Pemeliharaan
- Mengikuti praktik pengembangan perangkat lunak yang "baik" sangat penting saat bekerja dengan aplikasi paralel - terutama jika seseorang selain Anda harus bekerja dengan perangkat lunak tersebut.
- Rancangan
- Pengodean
- Debugging
- Tuning
- Pemeliharaan
Portabilitas
- Berkat standarisasi di beberapa API, seperti MPI, utas POSIX, dan OpenMP, masalah portabilitas dengan program paralel tidak seserius di tahun-tahun sebelumnya. Namun...
- Semua masalah portabilitas biasa yang terkait dengan program serial berlaku untuk program paralel. Misalnya, jika Anda menggunakan "perangkat tambahan" vendor untuk Fortran, C atau C ++, portabilitas akan menjadi masalah.
- Meskipun standar ada untuk beberapa API, penerapannya akan berbeda dalam beberapa detail, terkadang sampai memerlukan modifikasi kode untuk mempengaruhi portabilitas.
- Sistem operasi dapat memainkan peran kunci dalam masalah portabilitas kode.
- Arsitektur perangkat keras memiliki karakteristik yang sangat bervariasi dan dapat memengaruhi portabilitas.
Persyaratan Sumber Daya
- Maksud utama dari pemrograman paralel adalah untuk mengurangi waktu eksekusi jam dinding, namun untuk mencapai ini, lebih banyak waktu CPU diperlukan. Misalnya, kode paralel yang berjalan dalam 1 jam pada 8 prosesor sebenarnya menggunakan waktu CPU 8 jam.
- Jumlah memori yang dibutuhkan bisa lebih besar untuk kode paralel daripada kode serial, karena kebutuhan untuk mereplikasi data dan untuk overhead yang terkait dengan pustaka dan subsistem dukungan paralel.
- Untuk program paralel yang berjalan singkat, sebenarnya ada penurunan kinerja dibandingkan dengan implementasi serial serupa. Biaya overhead yang terkait dengan pengaturan lingkungan paralel, pembuatan tugas, komunikasi, dan penghentian tugas dapat terdiri dari porsi yang signifikan dari total waktu eksekusi untuk jangka pendek.
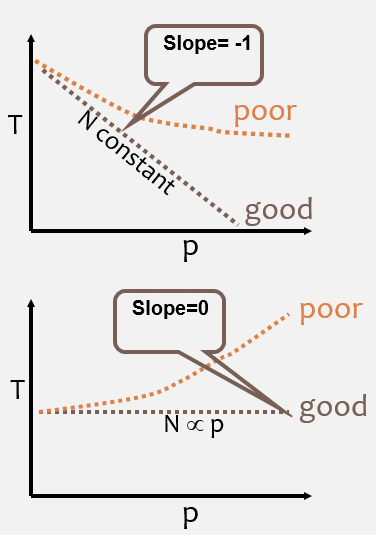
Skalabilitas
strongWeakScaling.gif
- Dua jenis penskalaan berdasarkan waktu ke solusi: penskalaan kuat dan penskalaan lemah.
- Penskalaan yang kuat:
- Ukuran masalah total tetap diperbaiki karena lebih banyak prosesor ditambahkan.
- Tujuannya adalah untuk menjalankan ukuran masalah yang sama lebih cepat
- Penskalaan sempurna berarti masalah diselesaikan dalam waktu 1 / P (dibandingkan dengan serial)
- Penskalaan lemah:
- Ukuran masalah per prosesor tetap diperbaiki karena lebih banyak prosesor ditambahkan. Ukuran masalah total sebanding dengan jumlah prosesor yang digunakan.
- Tujuannya adalah untuk menyelesaikan masalah yang lebih besar dalam waktu yang sama
- Penskalaan sempurna berarti masalah Px berjalan pada waktu yang sama saat prosesor tunggal dijalankan
- Kemampuan skala kinerja program paralel adalah hasil dari sejumlah faktor yang saling terkait. Cukup menambahkan lebih banyak prosesor jarang menjadi jawabannya.
- Algoritme mungkin memiliki batasan yang melekat pada skalabilitas. Pada titik tertentu, menambahkan lebih banyak sumber daya menyebabkan kinerja menurun. Ini adalah situasi umum dengan banyak aplikasi paralel.
- Faktor perangkat keras memainkan peran penting dalam skalabilitas. Contoh:
- Bandwidth bus memori-cpu pada mesin SMP
- Bandwidth jaringan komunikasi
- Jumlah memori yang tersedia di mesin atau set mesin tertentu
- Kecepatan jam prosesor
- Pustaka dukungan paralel dan perangkat lunak subsistem dapat membatasi skalabilitas terlepas dari aplikasi Anda.
- Ukuran masalah total tetap diperbaiki karena lebih banyak prosesor ditambahkan.
- Tujuannya adalah untuk menjalankan ukuran masalah yang sama lebih cepat
- Penskalaan sempurna berarti masalah diselesaikan dalam waktu 1 / P (dibandingkan dengan serial)
- Ukuran masalah per prosesor tetap diperbaiki karena lebih banyak prosesor ditambahkan. Ukuran masalah total sebanding dengan jumlah prosesor yang digunakan.
- Tujuannya adalah untuk menyelesaikan masalah yang lebih besar dalam waktu yang sama
- Penskalaan sempurna berarti masalah Px berjalan pada waktu yang sama saat prosesor tunggal dijalankan
- Bandwidth bus memori-cpu pada mesin SMP
- Bandwidth jaringan komunikasi
- Jumlah memori yang tersedia di mesin atau set mesin tertentu
- Kecepatan jam prosesor
Arsitektur Memori Komputer Paralel
Berbagi memori
Karakteristik umum
- Memori bersama komputer paralel sangat bervariasi, tetapi umumnya memiliki kesamaan kemampuan untuk semua prosesor untuk mengakses semua memori sebagai ruang alamat global.
- Beberapa prosesor dapat beroperasi secara independen tetapi berbagi sumber daya memori yang sama.
- Perubahan lokasi memori yang dilakukan oleh satu prosesor dapat dilihat oleh semua prosesor lainnya.
- Secara historis, mesin memori bersama telah diklasifikasikan sebagai UMA dan NUMA , berdasarkan waktu akses memori.
Uniform Memory Access (UMA)
- Paling sering diwakili hari ini oleh Symmetric Multiprocessor (SMP) mesin
- Prosesor identik
- Akses yang sama dan waktu akses ke memori
- Terkadang disebut CC-UMA - Cache Coherent UMA. Koheren cache berarti jika satu prosesor memperbarui lokasi di memori bersama, semua prosesor lain tahu tentang pembaruan tersebut. Koherensi cache dicapai di tingkat perangkat keras.
shared_mem.gif
")
Akses Memori Non-Seragam (NUMA)
- Seringkali dibuat dengan menghubungkan dua atau lebih SMP secara fisik
- Satu SMP bisa langsung mengakses memori SMP lain
- Tidak semua prosesor memiliki waktu akses yang sama ke semua memori
- Akses memori melalui link lebih lambat
- Jika koherensi cache dipertahankan, maka mungkin juga disebut CC-NUMA - Cache Coherent NUMA
numa.gif
")
Keuntungan
- Ruang alamat global memberikan perspektif pemrograman yang ramah pengguna ke memori
- Berbagi data antar tugas cepat dan seragam karena kedekatan memori dengan CPU
Kekurangan
- Kerugian utama adalah kurangnya skalabilitas antara memori dan CPU. Menambahkan lebih banyak CPU dapat secara geometris meningkatkan lalu lintas di jalur memori-CPU bersama, dan untuk sistem yang koheren cache, secara geometris meningkatkan lalu lintas yang terkait dengan cache / manajemen memori.
- Tanggung jawab programmer untuk konstruksi sinkronisasi yang memastikan akses "benar" dari memori global.
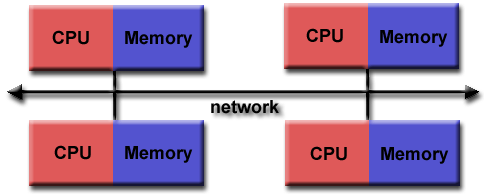
Memori Terdistribusi
Karakteristik umum
- Seperti sistem memori bersama, sistem memori terdistribusi sangat bervariasi tetapi memiliki karakteristik yang sama. Sistem memori terdistribusi memerlukan jaringan komunikasi untuk menghubungkan memori antar prosesor.
- Prosesor memiliki memori lokalnya sendiri. Alamat memori dalam satu prosesor tidak dipetakan ke prosesor lain, jadi tidak ada konsep ruang alamat global di semua prosesor.
- Karena setiap prosesor memiliki memori lokalnya sendiri, ia beroperasi secara independen. Perubahan yang dibuat pada memori lokalnya tidak berpengaruh pada memori prosesor lain. Karenanya, konsep koherensi cache tidak berlaku.
- Ketika prosesor membutuhkan akses ke data di prosesor lain, biasanya tugas programmer untuk secara eksplisit menentukan bagaimana dan kapan data dikomunikasikan. Sinkronisasi antar tugas juga menjadi tanggung jawab programmer.
- "Fabric" jaringan yang digunakan untuk transfer data sangat bervariasi, meskipun dapat sesederhana Ethernet.
didistribusikan_mem.gif
Keuntungan
- Memori dapat diskalakan dengan jumlah prosesor. Tingkatkan jumlah prosesor dan ukuran memori meningkat secara proporsional.
- Setiap prosesor dapat dengan cepat mengakses memorinya sendiri tanpa gangguan dan tanpa biaya tambahan yang timbul saat mencoba mempertahankan koherensi cache global.
- Efektivitas biaya: dapat menggunakan komoditas, prosesor siap pakai, dan jaringan.
Kekurangan
- Pemrogram bertanggung jawab atas banyak detail yang terkait dengan komunikasi data antar prosesor.
- Mungkin sulit untuk memetakan struktur data yang ada, berdasarkan memori global, ke organisasi memori ini.
- Waktu akses memori yang tidak seragam - data yang berada di node jauh membutuhkan waktu lebih lama untuk diakses daripada data lokal node.
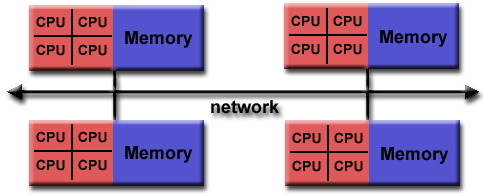
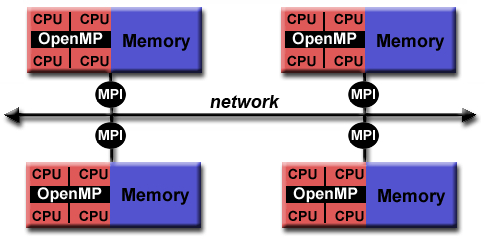
Memori Bersama-Terdistribusi Hibrid
Karakteristik umum
- Komputer terbesar dan tercepat di dunia saat ini menggunakan arsitektur memori bersama dan terdistribusi.
hybrid_mem.gif
hybrid_mem2.gif
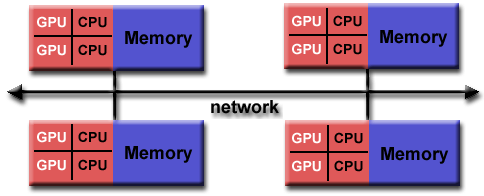
- Komponen memori bersama dapat berupa mesin memori bersama dan / atau unit pemrosesan grafis (GPU).
- Komponen memori terdistribusi adalah jaringan dari beberapa mesin memori / GPU bersama, yang hanya mengetahui memori mereka sendiri - bukan memori di komputer lain. Oleh karena itu, komunikasi jaringan diperlukan untuk memindahkan data dari satu mesin ke mesin lainnya.
- Tren saat ini tampaknya menunjukkan bahwa jenis arsitektur memori ini akan terus berlaku dan meningkat pada komputasi kelas atas di masa mendatang.
Keuntungan dan kerugian
- Apa pun yang umum untuk arsitektur memori bersama dan terdistribusi.
- Peningkatan skalabilitas merupakan keuntungan penting
- Kompleksitas programmer yang meningkat merupakan kerugian penting
Model Pemrograman Paralel
Gambaran
- Ada beberapa model pemrograman paralel yang umum digunakan:
- Memori Bersama (tanpa utas)
- Benang
- Memori Terdistribusi / Pengiriman Pesan
- Data Paralel
- Hibrida
- Program Tunggal Beberapa Data (SPMD)
- Beberapa Program Beberapa Data (MPMD)
- Model pemrograman paralel ada sebagai abstraksi di atas arsitektur perangkat keras dan memori.
- Meskipun mungkin tidak terlihat jelas, model ini TIDAK spesifik untuk jenis mesin atau arsitektur memori tertentu. Faktanya, salah satu model ini dapat (secara teoritis) diimplementasikan pada perangkat keras yang mendasarinya. Dua contoh dari masa lalu dibahas di bawah ini.
- Memori Bersama (tanpa utas)
- Benang
- Memori Terdistribusi / Pengiriman Pesan
- Data Paralel
- Hibrida
- Program Tunggal Beberapa Data (SPMD)
- Beberapa Program Beberapa Data (MPMD)
MODEL MEMORI SHARED PADA MESIN MEMORI DISTRIBUSI
Pendekatan ALLCACHE Kendall Square Research (KSR). Memori mesin didistribusikan secara fisik ke seluruh mesin dalam jaringan, tetapi tampak bagi pengguna sebagai satu ruang alamat global memori bersama. Secara umum, pendekatan ini disebut sebagai "memori bersama virtual".
modelAbstraction1.gif

ksr1.gif

MODEL MEMORI DISTRIBUTED PADA MESIN MEMORI SHARED
Message Passing Interface (MPI) pada SGI Origin 2000. SGI Origin 2000 menggunakan tipe CC-NUMA dari arsitektur memori bersama, di mana setiap tugas memiliki akses langsung ke ruang alamat global yang tersebar di semua mesin. Namun, kemampuan untuk mengirim dan menerima pesan menggunakan MPI, seperti yang biasa dilakukan melalui jaringan mesin memori terdistribusi, telah diterapkan dan umum digunakan.
modelAbstraction2.gif

sgiOrigin2000.jpeg

- Model mana yang akan digunakan? Ini sering kali merupakan kombinasi dari apa yang tersedia dan pilihan pribadi. Tidak ada model yang "terbaik", meskipun pasti ada implementasi yang lebih baik dari beberapa model dibandingkan yang lain.
- Bagian berikut menjelaskan masing-masing model yang disebutkan di atas, dan juga membahas beberapa implementasi aktualnya.
Model Memori Bersama (tanpa utas)
sharedMemoryModel.gif
- Dalam model pemrograman ini, proses / tugas berbagi ruang alamat yang sama, yang mereka baca dan tulis secara asinkron.
- Berbagai mekanisme seperti kunci / semaphore digunakan untuk mengontrol akses ke memori bersama, menyelesaikan perselisihan dan untuk mencegah kondisi balapan dan kebuntuan.
- Ini mungkin model pemrograman paralel yang paling sederhana.
- Keuntungan model ini dari sudut pandang pemrogram adalah bahwa gagasan tentang "kepemilikan" data kurang, sehingga tidak perlu secara eksplisit menjelaskan komunikasi data antar tugas. Semua proses melihat dan memiliki akses yang sama ke memori bersama. Pengembangan program seringkali dapat disederhanakan.
- Kerugian penting dalam hal kinerja adalah semakin sulitnya untuk memahami dan mengelola lokalitas data :
- Menjaga data tetap lokal ke proses yang berfungsi akan menghemat akses memori, penyegaran cache, dan lalu lintas bus yang terjadi ketika beberapa proses menggunakan data yang sama.
- Sayangnya, pengontrolan lokalitas data sulit dipahami dan mungkin berada di luar kendali pengguna rata-rata.
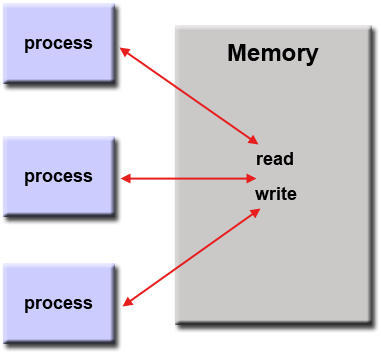
- Menjaga data tetap lokal ke proses yang berfungsi akan menghemat akses memori, penyegaran cache, dan lalu lintas bus yang terjadi ketika beberapa proses menggunakan data yang sama.
- Sayangnya, pengontrolan lokalitas data sulit dipahami dan mungkin berada di luar kendali pengguna rata-rata.
Implementasi:
- Pada mesin memori bersama yang berdiri sendiri, sistem operasi asli, kompiler dan / atau perangkat keras menyediakan dukungan untuk pemrograman memori bersama. Misalnya, standar POSIX menyediakan API untuk menggunakan memori bersama, dan UNIX menyediakan segmen memori bersama (shmget, shmat, shmctl, dll).
- Pada mesin memori terdistribusi, memori secara fisik didistribusikan ke seluruh jaringan mesin, tetapi dibuat global melalui perangkat keras dan perangkat lunak khusus. Berbagai implementasi SHMEM tersedia: http://en.wikipedia.org/wiki/SHMEM .
Model Benang
threadsModel2.gif
- Model pemrograman ini adalah jenis pemrograman memori bersama.
- Dalam model thread pemrograman paralel, satu proses "bobot berat" dapat memiliki beberapa jalur eksekusi bersamaan "bobot ringan".
- Sebagai contoh:
- Program utama a.out dijadwalkan untuk dijalankan oleh sistem operasi asli. a.out memuat dan memperoleh semua sistem dan sumber daya pengguna yang diperlukan untuk dijalankan. Ini adalah proses "beban berat".
- a.out melakukan beberapa pekerjaan serial, dan kemudian membuat sejumlah tugas (utas) yang dapat dijadwalkan dan dijalankan oleh sistem operasi secara bersamaan.
- Setiap utas memiliki data lokal, tetapi juga, membagikan seluruh sumber daya a.out . Ini menghemat overhead yang terkait dengan replikasi sumber daya program untuk setiap utas ("ringan"). Setiap utas juga mendapat manfaat dari tampilan memori global karena berbagi ruang memori a.out .
- Pekerjaan thread mungkin paling baik dijelaskan sebagai subrutin dalam program utama. Setiap utas dapat menjalankan subrutin apa pun secara bersamaan dengan utas lainnya.
- Utas berkomunikasi satu sama lain melalui memori global (memperbarui lokasi alamat). Ini membutuhkan konstruksi sinkronisasi untuk memastikan bahwa lebih dari satu utas tidak memperbarui alamat global yang sama setiap saat.
- Utas bisa datang dan pergi, tetapi a.out tetap ada untuk menyediakan sumber daya bersama yang diperlukan hingga aplikasi selesai.
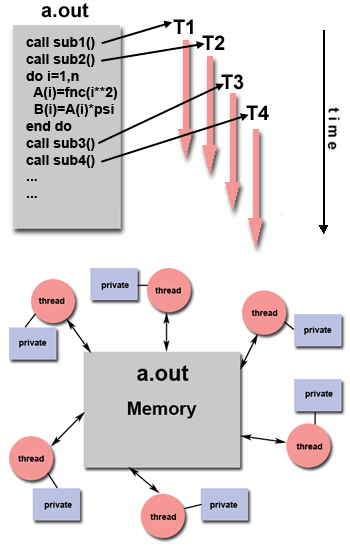
- Program utama a.out dijadwalkan untuk dijalankan oleh sistem operasi asli. a.out memuat dan memperoleh semua sistem dan sumber daya pengguna yang diperlukan untuk dijalankan. Ini adalah proses "beban berat".
- a.out melakukan beberapa pekerjaan serial, dan kemudian membuat sejumlah tugas (utas) yang dapat dijadwalkan dan dijalankan oleh sistem operasi secara bersamaan.
- Setiap utas memiliki data lokal, tetapi juga, membagikan seluruh sumber daya a.out . Ini menghemat overhead yang terkait dengan replikasi sumber daya program untuk setiap utas ("ringan"). Setiap utas juga mendapat manfaat dari tampilan memori global karena berbagi ruang memori a.out .
- Pekerjaan thread mungkin paling baik dijelaskan sebagai subrutin dalam program utama. Setiap utas dapat menjalankan subrutin apa pun secara bersamaan dengan utas lainnya.
- Utas berkomunikasi satu sama lain melalui memori global (memperbarui lokasi alamat). Ini membutuhkan konstruksi sinkronisasi untuk memastikan bahwa lebih dari satu utas tidak memperbarui alamat global yang sama setiap saat.
- Utas bisa datang dan pergi, tetapi a.out tetap ada untuk menyediakan sumber daya bersama yang diperlukan hingga aplikasi selesai.
Implementasi:
- Dari perspektif pemrograman, implementasi utas biasanya terdiri dari:
- Pustaka subrutin yang dipanggil dari dalam kode sumber paralel
- Satu set arahan kompilator yang tertanam dalam kode sumber serial atau paralel
Dalam kedua kasus tersebut, programmer bertanggung jawab untuk menentukan paralelisme (meskipun kompiler terkadang dapat membantu).
- Implementasi berulir bukanlah hal baru dalam komputasi. Secara historis, vendor perangkat keras telah menerapkan versi utas milik mereka sendiri. Implementasi ini sangat berbeda satu sama lain sehingga menyulitkan pemrogram untuk mengembangkan aplikasi berulir portabel.
- Upaya standardisasi yang tidak terkait telah menghasilkan dua implementasi utas yang sangat berbeda: Utas POSIX dan OpenMP.
UTAS POSIX
- Ditentukan oleh standar IEEE POSIX 1003.1c (1995). C Bahasa saja.
- Bagian dari sistem operasi Unix / Linux
- Berbasis perpustakaan
- Biasa disebut sebagai Pthreads.
- Paralelisme yang sangat eksplisit; membutuhkan perhatian programmer yang signifikan terhadap detail.
OPENMP
- Standar industri, didefinisikan bersama dan didukung oleh sekelompok vendor perangkat keras dan perangkat lunak komputer utama, organisasi dan individu.
- Berbasis direktif kompiler
- Portabel / multi-platform, termasuk platform Unix dan Windows
- Tersedia dalam implementasi C / C ++ dan Fortran
- Bisa sangat mudah dan sederhana untuk digunakan - menyediakan "paralelisme tambahan". Bisa dimulai dengan kode serial.
- Penerapan berulir lainnya biasa terjadi, tetapi tidak dibahas di sini:
- Utas Microsoft
- Java, utas Python
- Benang CUDA untuk GPU
- Utas Microsoft
- Java, utas Python
- Benang CUDA untuk GPU
Informasi Lebih Lanjut
- Tutorial POSIX Threads: computing.llnl.gov/tutorials/pthreads
- Tutorial OpenMP: computing.llnl.gov/tutorials/openMP
Model Penyaluran Memori / Pesan Terdistribusi
msg_pass_model.gif
- Model ini menunjukkan karakteristik berikut:
- Serangkaian tugas yang menggunakan memori lokalnya sendiri selama komputasi. Beberapa tugas dapat berada di mesin fisik yang sama dan / atau di sejumlah mesin yang berubah-ubah.
- Tugas bertukar data melalui komunikasi dengan mengirim dan menerima pesan.
- Transfer data biasanya membutuhkan operasi kooperatif yang akan dilakukan oleh setiap proses. Misalnya, operasi pengiriman harus memiliki operasi terima yang cocok.
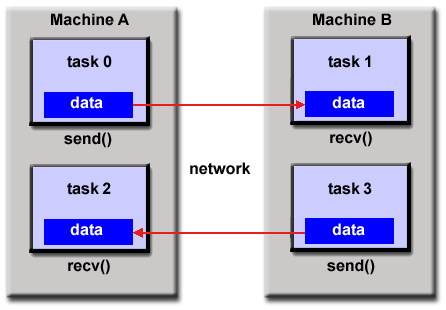
- Serangkaian tugas yang menggunakan memori lokalnya sendiri selama komputasi. Beberapa tugas dapat berada di mesin fisik yang sama dan / atau di sejumlah mesin yang berubah-ubah.
- Tugas bertukar data melalui komunikasi dengan mengirim dan menerima pesan.
- Transfer data biasanya membutuhkan operasi kooperatif yang akan dilakukan oleh setiap proses. Misalnya, operasi pengiriman harus memiliki operasi terima yang cocok.
Implementasi:
- Dari perspektif pemrograman, implementasi penyampaian pesan biasanya terdiri dari pustaka subrutin. Panggilan ke subrutin ini tertanam dalam kode sumber. Programmer bertanggung jawab untuk menentukan semua paralelisme.
- Secara historis, berbagai pustaka penyampaian pesan telah tersedia sejak 1980-an. Implementasi ini sangat berbeda satu sama lain sehingga menyulitkan pemrogram untuk mengembangkan aplikasi portabel.
- Pada tahun 1992, MPI Forum dibentuk dengan tujuan utama membangun antarmuka standar untuk implementasi penyampaian pesan.
- Bagian 1 dari Message Passing Interface (MPI) dirilis pada tahun 1994. Bagian 2 (MPI-2) dirilis pada tahun 1996 dan MPI-3 pada tahun 2012. Semua spesifikasi MPI tersedia di web di http: //www.mpi- forum.org/docs/ .
- MPI adalah standar industri "de facto" untuk penyampaian pesan, menggantikan hampir semua penerapan penyampaian pesan lainnya yang digunakan untuk pekerjaan produksi. Implementasi MPI ada untuk hampir semua platform komputasi paralel yang populer. Tidak semua implementasi menyertakan semua yang ada di MPI-1, MPI-2 atau MPI-3.
Informasi Lebih Lanjut
- Tutorial MPI: computing.llnl.gov/tutorials/mpi
Model Data Paralel
data_parallel_model.gif
- Mungkin juga disebut sebagai model Partitioned Global Address Space (PGAS) .
- Model paralel data menunjukkan karakteristik berikut:
- Ruang alamat diperlakukan secara global
- Sebagian besar pekerjaan paralel berfokus pada melakukan operasi pada kumpulan data. Kumpulan data biasanya diatur ke dalam struktur umum, seperti larik atau kubus.
- Sekumpulan tugas bekerja secara kolektif pada struktur data yang sama, namun, setiap tugas bekerja pada partisi yang berbeda dari struktur data yang sama.
- Tugas melakukan operasi yang sama pada partisi kerja mereka, misalnya, "tambahkan 4 ke setiap elemen array".
- Pada arsitektur memori bersama, semua tugas mungkin memiliki akses ke struktur data melalui memori global.
- Pada arsitektur memori terdistribusi, struktur data global dapat dipisahkan secara logis dan / atau fisik di seluruh tugas.
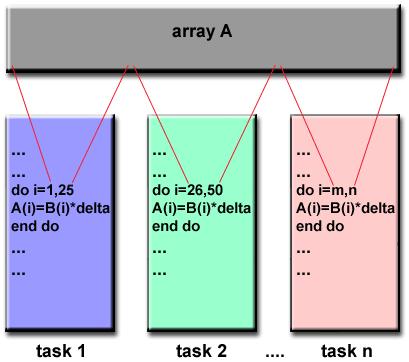
- Ruang alamat diperlakukan secara global
- Sebagian besar pekerjaan paralel berfokus pada melakukan operasi pada kumpulan data. Kumpulan data biasanya diatur ke dalam struktur umum, seperti larik atau kubus.
- Sekumpulan tugas bekerja secara kolektif pada struktur data yang sama, namun, setiap tugas bekerja pada partisi yang berbeda dari struktur data yang sama.
- Tugas melakukan operasi yang sama pada partisi kerja mereka, misalnya, "tambahkan 4 ke setiap elemen array".
Implementasi:
- Saat ini, ada beberapa implementasi pemrograman paralel yang relatif populer, dan terkadang bersifat pengembangan, berdasarkan model Data Parallel / PGAS.
- Coarray Fortran: sekumpulan kecil ekstensi ke Fortran 95 untuk pemrograman paralel SPMD. Tergantung kompiler. Informasi lebih lanjut: https://en.wikipedia.org/wiki/Coarray_Fortran
- Unified Parallel C (UPC): ekstensi ke bahasa pemrograman C untuk pemrograman paralel SPMD. Tergantung kompiler. Informasi lebih lanjut: https://upc.lbl.gov/
- Global Array: menyediakan lingkungan pemrograman gaya memori bersama dalam konteks struktur data array terdistribusi. Perpustakaan domain publik dengan binding C dan Fortran77. Informasi lebih lanjut: https://en.wikipedia.org/wiki/Global_Arrays
- X10: bahasa pemrograman paralel berbasis PGAS yang sedang dikembangkan oleh IBM di Pusat Penelitian Thomas J. Watson. Informasi lebih lanjut: http://x10-lang.org/
- Kapel: proyek bahasa pemrograman paralel open source yang dipimpin oleh Cray. Informasi lebih lanjut: http://chapel.cray.com/
Model Hibrida
hybrid_model.gif
hybrid_model2.gif
- Model hybrid menggabungkan lebih dari satu model pemrograman yang dijelaskan sebelumnya.
- Saat ini, contoh umum model hybrid adalah kombinasi dari message passing model (MPI) dengan model threads (OpenMP).
- Thread melakukan kernel intensif komputasi menggunakan data lokal pada node
- Komunikasi antar proses pada node yang berbeda terjadi melalui jaringan menggunakan MPI
- Model hybrid ini cocok untuk lingkungan perangkat keras yang paling populer (saat ini) dari mesin multi / banyak-inti berkerumun.
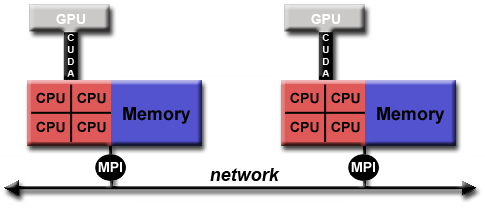
- Contoh model hybrid lain yang serupa dan semakin populer adalah menggunakan MPI dengan pemrograman CPU-GPU (Graphics Processing Unit).
- Tugas MPI dijalankan pada CPU menggunakan memori lokal dan berkomunikasi satu sama lain melalui jaringan.
- Kernel yang secara komputasi intensif di-off-load ke GPU di node.
- Pertukaran data antara memori node-lokal dan GPU menggunakan CUDA (atau yang setara).
- Model hybrid lainnya adalah umum:
- MPI dengan Pthreads
- MPI dengan akselerator non-GPU
- ...
- Thread melakukan kernel intensif komputasi menggunakan data lokal pada node
- Komunikasi antar proses pada node yang berbeda terjadi melalui jaringan menggunakan MPI
- Tugas MPI dijalankan pada CPU menggunakan memori lokal dan berkomunikasi satu sama lain melalui jaringan.
- Kernel yang secara komputasi intensif di-off-load ke GPU di node.
- Pertukaran data antara memori node-lokal dan GPU menggunakan CUDA (atau yang setara).
- MPI dengan Pthreads
- MPI dengan akselerator non-GPU
- ...
SPMD dan MPMD
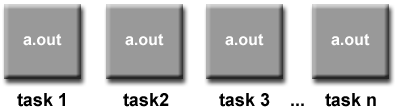
Program Tunggal Beberapa Data (SPMD)
spmd_model.gif
- SPMD sebenarnya adalah model pemrograman "tingkat tinggi" yang dapat dibangun di atas kombinasi model pemrograman paralel yang disebutkan sebelumnya.
- PROGRAM TUNGGAL: Semua tugas menjalankan salinannya dari program yang sama secara bersamaan. Program ini dapat berupa utas, penyampaian pesan, data paralel atau hibrid.
- GANDA DATA: Semua tugas mungkin menggunakan data yang berbeda
- Program SPMD biasanya memiliki logika yang diperlukan yang diprogram ke dalamnya untuk memungkinkan tugas yang berbeda untuk bercabang atau hanya mengeksekusi secara bersyarat bagian-bagian dari program yang dirancang untuk dieksekusi. Artinya, tugas tidak harus menjalankan seluruh program - mungkin hanya sebagian saja.
- Model SPMD, menggunakan message passing atau hybrid programming, mungkin merupakan model pemrograman paralel yang paling umum digunakan untuk cluster multi-node.
Beberapa Program Beberapa Data (MPMD)
mpmd_model.gif
- Seperti SPMD, MPMD sebenarnya adalah model pemrograman "tingkat tinggi" yang dapat dibangun di atas kombinasi model pemrograman paralel yang disebutkan sebelumnya.
- PROGRAM GANDA: Tugas dapat menjalankan program yang berbeda secara bersamaan. Program dapat berupa utas, penyampaian pesan, data paralel atau hibrid.
- GANDA DATA: Semua tugas mungkin menggunakan data yang berbeda
- Aplikasi MPMD tidak umum seperti aplikasi SPMD, tetapi mungkin lebih cocok untuk jenis masalah tertentu, terutama yang lebih cocok untuk dekomposisi fungsional daripada dekomposisi domain (dibahas nanti di bagian Partisi).

Merancang Program Paralel
Paralelisasi Otomatis vs. Manual
- Merancang dan mengembangkan program paralel secara khas merupakan proses yang sangat manual. Pemrogram biasanya bertanggung jawab untuk mengidentifikasi dan benar-benar menerapkan paralelisme.
- Sangat sering, mengembangkan kode paralel secara manual adalah proses yang memakan waktu, kompleks, rawan kesalahan, dan berulang.
- Selama beberapa tahun sekarang, berbagai alat telah tersedia untuk membantu programmer dengan mengubah program serial menjadi program paralel. Jenis alat yang paling umum digunakan untuk memparalelkan program serial secara otomatis adalah kompiler atau pra-prosesor yang memparalelkan.
- Kompiler paralelisasi umumnya bekerja dalam dua cara berbeda:
SEPENUHNYA OTOMATIS
- Kompilator menganalisis kode sumber dan mengidentifikasi peluang untuk paralelisme.
- Analisis tersebut termasuk mengidentifikasi penghambat paralelisme dan mungkin pembobotan biaya pada apakah paralelisme benar-benar akan meningkatkan kinerja atau tidak.
- Loop (do, for) adalah target yang paling sering untuk paralelisasi otomatis.
PROGRAMMER DISUTRADARAI
- Dengan menggunakan "perintah kompilator" atau mungkin tanda kompilator, pemrogram secara eksplisit memberi tahu kompilator cara memparalelkan kode.
- Mungkin juga dapat digunakan bersama dengan beberapa derajat paralelisasi otomatis.
- Paralelisasi yang dihasilkan kompiler paling umum dilakukan menggunakan memori dan utas bersama pada node (seperti OpenMP).
- Jika Anda memulai dengan kode serial yang ada dan memiliki kendala waktu atau anggaran, maka paralelisasi otomatis mungkin jawabannya. Namun, ada beberapa peringatan penting yang berlaku untuk paralelisasi otomatis:
- Hasil yang salah mungkin dihasilkan
- Performa sebenarnya bisa menurun
- Jauh kurang fleksibel dibandingkan paralelisasi manual
- Terbatas pada subset (kebanyakan loop) kode
- Sebenarnya tidak dapat memparalelkan kode jika analisis kompiler menunjukkan ada penghambat atau kode terlalu rumit
- Sisa dari bagian ini berlaku untuk metode manual mengembangkan kode paralel.
- Hasil yang salah mungkin dihasilkan
- Performa sebenarnya bisa menurun
- Jauh kurang fleksibel dibandingkan paralelisasi manual
- Terbatas pada subset (kebanyakan loop) kode
- Sebenarnya tidak dapat memparalelkan kode jika analisis kompiler menunjukkan ada penghambat atau kode terlalu rumit
Pahami Masalah dan Programnya
hotspotBottleneck2.jpeg
- Tidak diragukan lagi, langkah pertama dalam mengembangkan perangkat lunak paralel adalah pertama-tama memahami masalah yang ingin Anda selesaikan secara paralel. Jika Anda memulai dengan program serial, ini memerlukan pemahaman kode yang ada juga.
- Sebelum menghabiskan waktu dalam upaya mengembangkan solusi paralel untuk suatu masalah, tentukan apakah masalah tersebut benar-benar dapat diparalelkan atau tidak.
- Contoh masalah yang mudah diparalelkan:

- Contoh masalah yang mudah diparalelkan:
Hitung energi potensial untuk masing-masing dari beberapa ribu konformasi independen sebuah molekul. Setelah selesai, tentukan konformasi energi minimum.
Masalah ini bisa diselesaikan secara paralel. Setiap konformasi molekuler dapat ditentukan secara independen. Perhitungan konformasi energi minimum juga merupakan masalah yang dapat diparalelkan.
- Contoh masalah dengan sedikit ke tidak ada paralelisme:
Penghitungan nilai F (n) menggunakan nilai F (n-1) dan F (n-2), yang harus dihitung terlebih dahulu.
- Identifikasi hotspot program :
- Ketahui di mana sebagian besar pekerjaan sebenarnya dilakukan. Mayoritas program ilmiah dan teknis biasanya menyelesaikan sebagian besar pekerjaan mereka di beberapa tempat.
- Profiler dan alat analisis kinerja dapat membantu di sini
- Fokus pada memparalelkan hotspot dan abaikan bagian-bagian program yang menjelaskan penggunaan CPU yang sedikit.
- Identifikasi kemacetan dalam program:
- Apakah ada area yang lambat secara tidak proporsional, atau menyebabkan pekerjaan yang dapat diparalelkan terhenti atau ditunda? Misalnya, I / O biasanya merupakan sesuatu yang memperlambat program.
- Mungkin dimungkinkan untuk merestrukturisasi program atau menggunakan algoritma yang berbeda untuk mengurangi atau menghilangkan area lambat yang tidak perlu
- Identifikasi penghambat paralelisme. Salah satu kelas penghambat yang umum adalah ketergantungan data , seperti yang ditunjukkan oleh deret Fibonacci di atas.
- Selidiki algoritme lain jika memungkinkan. Ini mungkin satu-satunya pertimbangan terpenting saat merancang aplikasi paralel.
- Manfaatkan perangkat lunak paralel pihak ketiga yang dioptimalkan dan pustaka matematika yang sangat dioptimalkan yang tersedia dari vendor terkemuka (ESSL IBM, MKL Intel, AMCL AMD, dll.).
Mempartisi
- Salah satu langkah pertama dalam mendesain program paralel adalah memecah masalah menjadi "potongan" pekerjaan yang terpisah yang dapat didistribusikan ke beberapa tugas. Ini dikenal sebagai dekomposisi atau partisi.
- Ada dua cara dasar untuk mempartisi pekerjaan komputasi di antara tugas-tugas paralel: dekomposisi domain dan dekomposisi fungsional .
Dekomposisi Domain
- Dalam jenis partisi ini, data yang terkait dengan masalah diuraikan. Setiap tugas paralel kemudian bekerja pada sebagian data.
domain_decomp.gif
- Ada berbagai cara untuk mempartisi data:
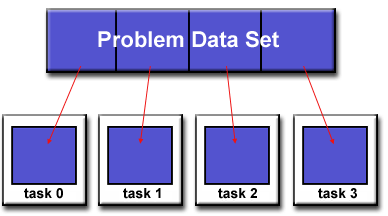
distributions.gif
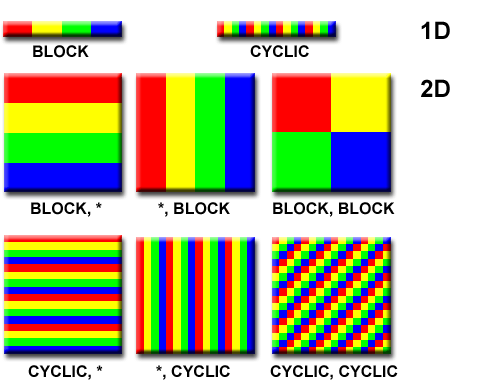
Dekomposisi Fungsional
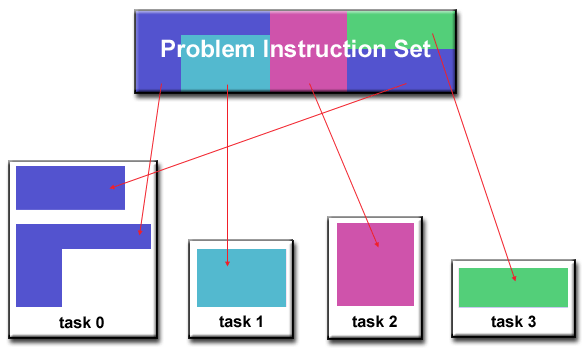
- Dalam pendekatan ini, fokusnya adalah pada komputasi yang akan dilakukan, bukan pada data yang dimanipulasi oleh komputasi. Masalah diuraikan sesuai dengan pekerjaan yang harus dilakukan. Setiap tugas kemudian melakukan sebagian dari keseluruhan pekerjaan.
functional_decomp.gif
- Dekomposisi fungsional cocok untuk masalah yang dapat dibagi menjadi tugas yang berbeda. Sebagai contoh:
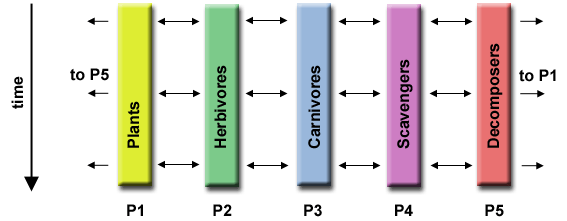
PEMODELAN EKOSISTEM
Setiap program menghitung populasi kelompok tertentu, di mana pertumbuhan setiap kelompok bergantung pada tetangganya. Seiring berjalannya waktu, setiap proses menghitung keadaannya saat ini, kemudian bertukar informasi dengan populasi tetangga. Semua tugas kemudian maju untuk menghitung keadaan pada langkah waktu berikutnya.
fungsional_ex1.gif
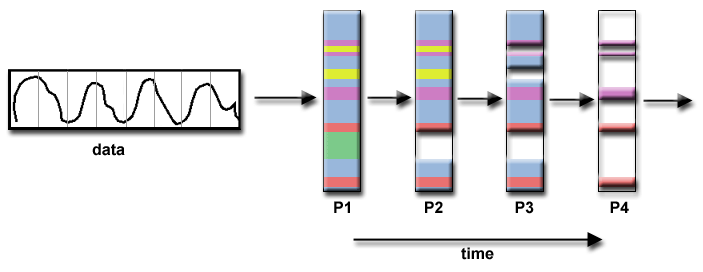
PEMROSESAN SINYAL
Kumpulan data sinyal audio dilewatkan melalui empat filter komputasi yang berbeda. Setiap filter adalah proses terpisah. Segmen data pertama harus melewati filter pertama sebelum melanjutkan ke yang kedua. Jika ya, segmen data kedua melewati filter pertama. Pada saat segmen data keempat berada di filter pertama, keempat tugas tersebut sibuk.
fungsional_ex2.gif
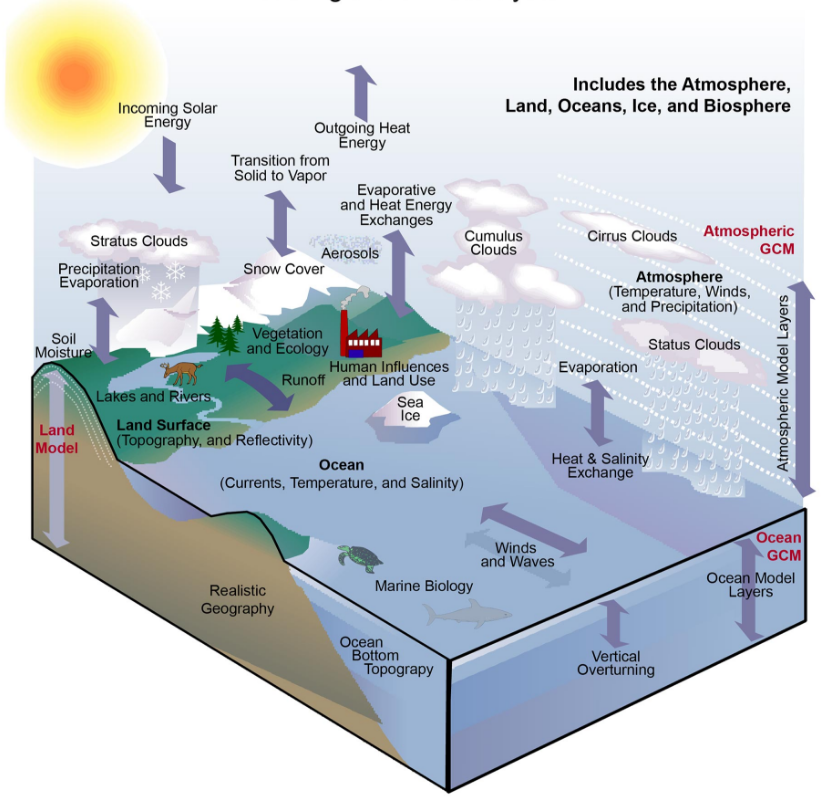
PEMODELAN IKLIM
Setiap komponen model dapat dianggap sebagai tugas terpisah. Panah merepresentasikan pertukaran data antar komponen selama komputasi: model atmosfer menghasilkan data kecepatan angin yang digunakan oleh model samudra, model samudra menghasilkan data suhu permukaan laut yang digunakan oleh model atmosfer, dan seterusnya.
fungsional_ex3.gif
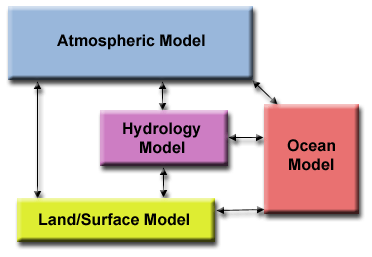
iklimModelling.png
- Menggabungkan kedua jenis penguraian masalah ini adalah hal biasa dan alami.
Komunikasi
Siapa yang Membutuhkan Komunikasi?
- Kebutuhan komunikasi antar tugas tergantung pada masalah Anda:
ANDA TIDAK MEMBUTUHKAN KOMUNIKASI
- Beberapa jenis masalah dapat diuraikan dan dijalankan secara paralel tanpa perlu tugas untuk berbagi data. Jenis masalah ini sering disebut paralel memalukan - sedikit atau tidak ada komunikasi yang diperlukan.
- Misalnya, bayangkan operasi pemrosesan gambar di mana setiap piksel dalam gambar hitam dan putih harus dibalik warnanya. Data gambar dapat dengan mudah didistribusikan ke beberapa tugas yang kemudian bertindak secara independen satu sama lain untuk melakukan bagian pekerjaan mereka.
black2white.gif

ANDA DO MEMBUTUHKAN KOMUNIKASI
- Kebanyakan aplikasi paralel tidak sesederhana itu, dan memang membutuhkan tugas untuk berbagi data satu sama lain.
- Misalnya, masalah difusi panas 2-D memerlukan tugas untuk mengetahui suhu yang dihitung oleh tugas yang memiliki data bersebelahan. Perubahan ke data tetangga memiliki efek langsung pada data tugas itu.
heat_partitioned.gif
Faktor yang Perlu Dipertimbangkan
Ada sejumlah faktor penting yang perlu dipertimbangkan saat merancang komunikasi antar-tugas program Anda:
OVERHEAD KOMUNIKASI
commOverhead.jpeg
- Komunikasi antar-tugas hampir selalu menyiratkan overhead.
- Siklus mesin dan sumber daya yang dapat digunakan untuk komputasi malah digunakan untuk mengemas dan mengirimkan data.
- Komunikasi sering kali memerlukan beberapa jenis sinkronisasi antar tugas, yang dapat mengakibatkan tugas menghabiskan waktu "menunggu" alih-alih melakukan pekerjaan.
- Lalu lintas komunikasi yang bersaing dapat memenuhi bandwidth jaringan yang tersedia, yang selanjutnya memperburuk masalah kinerja.

LATENSI VS. BANDWIDTH
- Latensi adalah waktu yang diperlukan untuk mengirim pesan minimal (0 byte) dari titik A ke titik B. Biasanya dinyatakan sebagai mikrodetik.
- Bandwidth adalah jumlah data yang dapat dikomunikasikan per satuan waktu. Biasanya dinyatakan sebagai megabyte / detik atau gigabyte / detik.
- Mengirim banyak pesan kecil dapat menyebabkan latensi mendominasi overhead komunikasi. Seringkali lebih efisien untuk mengemas pesan kecil menjadi pesan yang lebih besar, sehingga meningkatkan bandwidth komunikasi yang efektif.
VISIBILITAS KOMUNIKASI
- Dengan Model Message Passing, komunikasi yang eksplisit dan umumnya cukup terlihat dan di bawah kendali programmer.
- Dengan Model Paralel Data, komunikasi sering terjadi secara transparan kepada programmer, terutama pada arsitektur memori terdistribusi. Pemrogram bahkan mungkin tidak dapat mengetahui dengan tepat bagaimana komunikasi antar-tugas dilakukan.
KOMUNIKASI SINKRON VS KOMUNIKASI ASINKRON
- Komunikasi sinkron memerlukan beberapa jenis "jabat tangan" di antara tugas-tugas yang berbagi data. Ini dapat secara eksplisit disusun dalam kode oleh programmer, atau mungkin terjadi pada level yang lebih rendah yang tidak diketahui oleh programmer.
- Komunikasi sinkron sering disebut sebagai komunikasi pemblokiran karena pekerjaan lain harus menunggu hingga komunikasi selesai.
- Komunikasi asinkron memungkinkan tugas untuk mentransfer data secara independen dari satu sama lain. Misalnya, tugas 1 dapat mempersiapkan dan mengirim pesan ke tugas 2, lalu segera mulai melakukan pekerjaan lain. Ketika tugas 2 benar-benar menerima data tidak masalah.
- Komunikasi asinkron sering disebut sebagai komunikasi non-pemblokiran karena pekerjaan lain dapat dilakukan saat komunikasi berlangsung.
- Interleaving komputasi dengan komunikasi adalah satu-satunya manfaat terbesar untuk menggunakan komunikasi asynchronous.
LINGKUP KOMUNIKASI
- Mengetahui tugas mana yang harus saling berkomunikasi sangat penting selama tahap desain kode paralel. Kedua scoping yang dijelaskan di bawah ini dapat diimplementasikan secara sinkron atau asinkron.
- Point-to-point - melibatkan dua tugas dengan satu tugas bertindak sebagai pengirim / produsen data, dan tugas lainnya bertindak sebagai penerima / konsumen.
- Kolektif - melibatkan berbagi data antara lebih dari dua tugas, yang sering ditentukan sebagai anggota dalam kelompok umum, atau kolektif. Beberapa variasi umum (masih ada lagi):
kolektif_comm.gif
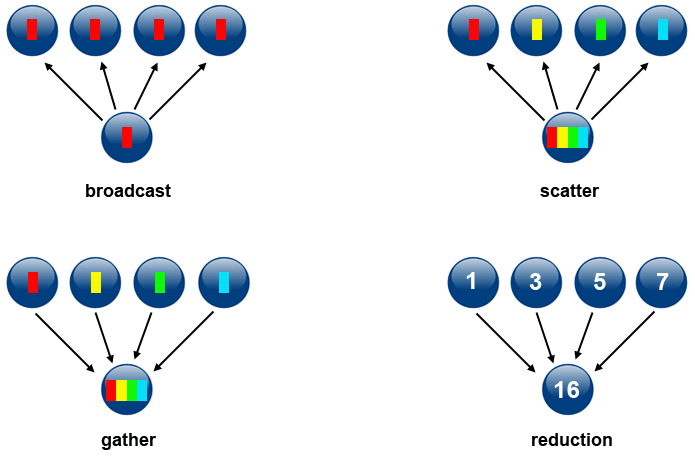
EFISIENSI KOMUNIKASI
- Seringkali, programmer memiliki pilihan yang dapat mempengaruhi kinerja komunikasi. Hanya sedikit yang disebutkan di sini.
- Implementasi mana untuk model tertentu yang harus digunakan? Menggunakan Message Passing Model sebagai contoh, satu implementasi MPI mungkin lebih cepat pada platform perangkat keras tertentu daripada yang lain.
- Jenis operasi komunikasi apa yang harus digunakan? Seperti disebutkan sebelumnya, operasi komunikasi asinkron dapat meningkatkan kinerja program secara keseluruhan.
- Struktur jaringan — platform yang berbeda menggunakan jaringan yang berbeda. Beberapa jaringan berkinerja lebih baik daripada yang lain. Memilih platform dengan jaringan yang lebih cepat mungkin bisa menjadi pilihan.
OVERHEAD DAN COMPLEXITY
helloWorldParallelCallgraph.gif
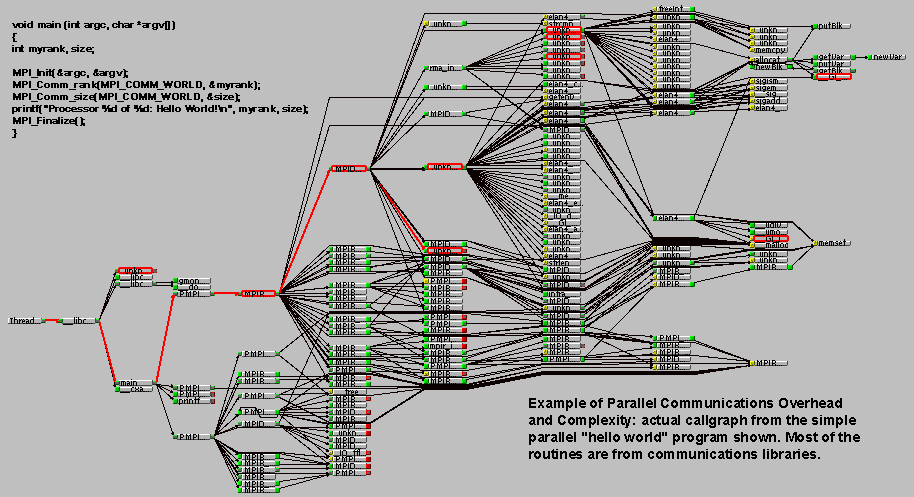
- Akhirnya, sadari bahwa ini hanyalah sebagian dari daftar hal-hal yang perlu dipertimbangkan!
Sinkronisasi
- Mengelola urutan pekerjaan dan tugas yang melakukannya adalah pertimbangan desain penting untuk sebagian besar program paralel.
- Dapat menjadi faktor penting dalam kinerja program (atau kekurangannya)
- Seringkali membutuhkan "serialisasi" dari segmen program.
sychronization2.jpeg

Jenis Sinkronisasi
PEMBATAS
- Biasanya menyiratkan bahwa semua tugas terlibat
- Setiap tugas melakukan tugasnya hingga mencapai penghalang. Kemudian berhenti, atau "memblokir".
- Saat tugas terakhir mencapai penghalang, semua tugas disinkronkan.
- Apa yang terjadi dari sini berbeda-beda. Seringkali, bagian serial dari pekerjaan harus dilakukan. Dalam kasus lain, tugas secara otomatis dirilis untuk melanjutkan pekerjaannya.
KUNCI / SEMAPHORE
- Dapat melibatkan sejumlah tugas
- Biasanya digunakan untuk membuat serial (melindungi) akses ke data global atau bagian kode. Hanya satu tugas dalam satu waktu yang dapat menggunakan (memiliki) kunci / semaphore / bendera.
- Tugas pertama untuk mendapatkan kunci "set" itu. Tugas ini kemudian dapat dengan aman (serial) mengakses data atau kode yang dilindungi.
- Tugas lain dapat mencoba untuk mendapatkan kunci tersebut tetapi harus menunggu hingga tugas yang memiliki kunci tersebut melepaskannya.
- Bisa memblokir atau tidak memblokir.
OPERASI KOMUNIKASI SINKRON
- Hanya melibatkan tugas-tugas yang menjalankan operasi komunikasi.
- Saat tugas melakukan operasi komunikasi, beberapa bentuk koordinasi diperlukan dengan tugas lain yang berpartisipasi dalam komunikasi tersebut. Misalnya, sebelum tugas bisa melakukan operasi pengiriman, itu harus terlebih dahulu menerima pengakuan dari tugas penerima yang boleh dikirim.
- Dibahas sebelumnya di bagian Komunikasi.
Dependensi Data
Definisi
- Ada ketergantungan antara pernyataan program ketika urutan eksekusi pernyataan mempengaruhi hasil program.
- Sebuah ketergantungan Data hasil dari beberapa penggunaan lokasi yang sama (s) dalam penyimpanan oleh tugas yang berbeda.
- Dependensi penting untuk pemrograman paralel karena mereka adalah salah satu penghambat utama paralelisme.
dependencies1.jpeg
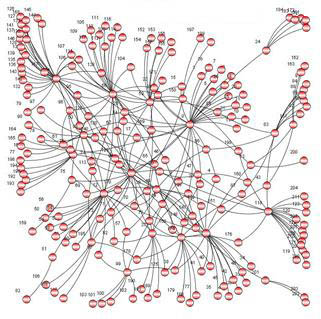
Contoh
LOOP MEMBAWA KETERGANTUNGAN DATA
DO J = MYSTART, MYEND A (J) = A (J-1) * 2.0 END DO
- Nilai A (J-1) harus dihitung sebelum nilai A (J), oleh karena itu A (J) menunjukkan ketergantungan data pada A (J-1). Paralelisme dihambat.
- Jika Tugas 2 memiliki A (J) dan tugas 1 memiliki A (J-1), menghitung nilai A (J) yang benar memerlukan:
- Arsitektur memori terdistribusi - tugas 2 harus mendapatkan nilai A (J-1) dari tugas 1 setelah tugas 1 menyelesaikan komputasinya
- Arsitektur memori bersama - tugas 2 harus membaca A (J-1) setelah tugas 1 memperbaruinya
- Arsitektur memori terdistribusi - tugas 2 harus mendapatkan nilai A (J-1) dari tugas 1 setelah tugas 1 menyelesaikan komputasinya
- Arsitektur memori bersama - tugas 2 harus membaca A (J-1) setelah tugas 1 memperbaruinya
LOOP KETERGANTUNGAN DATA INDEPENDEN
tugas 1 tugas 2 ------ ------
X = 2 X = 4 . . . . Y = X ** 2 Y = X ** 3
- Seperti contoh sebelumnya, paralelisme dihambat. Nilai Y bergantung pada:
- Arsitektur memori terdistribusi - jika atau ketika nilai X dikomunikasikan di antara tugas-tugas.
- Arsitektur memori bersama - tugas yang terakhir menyimpan nilai X.
- Meskipun semua dependensi data penting untuk diidentifikasi saat merancang program paralel, dependensi yang dibawa loop sangat penting karena loop mungkin merupakan target paling umum dari upaya paralelisasi.
- Arsitektur memori terdistribusi - jika atau ketika nilai X dikomunikasikan di antara tugas-tugas.
- Arsitektur memori bersama - tugas yang terakhir menyimpan nilai X.
Bagaimana Menangani Dependensi Data
- Arsitektur memori terdistribusi - mengkomunikasikan data yang diperlukan pada titik sinkronisasi.
- Arsitektur memori bersama -sinkronisasi operasi baca / tulis antar tugas.
Penyeimbang beban
- Penyeimbangan beban mengacu pada praktik mendistribusikan jumlah pekerjaan yang kira-kira sama di antara tugas-tugas sehingga semua tugas tetap sibuk sepanjang waktu. Ini dapat dianggap sebagai meminimalkan waktu idle tugas.
- Penyeimbangan beban penting untuk program paralel karena alasan kinerja. Misalnya, jika semua tugas tunduk pada titik sinkronisasi penghalang, tugas paling lambat akan menentukan kinerja keseluruhan.
load_bal1.gif
loadImbalance2.jpeg

Cara Mencapai Saldo Beban
PARTISI YANG SAMA UNTUK PEKERJAAN YANG DITERIMA SETIAP TUGAS
- Untuk operasi array / matriks di mana setiap tugas melakukan pekerjaan serupa, distribusikan kumpulan data secara merata di antara tugas-tugas.
- Untuk iterasi perulangan di mana pekerjaan yang dilakukan di setiap iterasi serupa, mendistribusikan iterasi secara merata di seluruh tugas.
- Jika campuran mesin yang heterogen dengan karakteristik kinerja yang berbeda-beda digunakan, pastikan untuk menggunakan beberapa jenis alat analisis kinerja untuk mendeteksi ketidakseimbangan beban. Sesuaikan pekerjaan dengan benar.
GUNAKAN TUGAS KERJA YANG DINAMIS
- Kelas-kelas masalah tertentu mengakibatkan ketidakseimbangan beban meskipun data didistribusikan secara merata di antara tugas-tugas:
sparseMatrix.gif
adaptiveGrid.jpeg
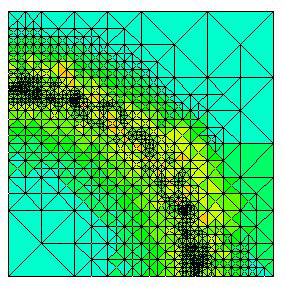
n-body.jpeg
| Array renggang - beberapa tugas akan memiliki data aktual untuk dikerjakan sementara yang lain sebagian besar memiliki "nol". | Metode grid adaptif - beberapa tugas mungkin perlu menyempurnakan mesh mereka sementara yang lain tidak. | Simulasi N-body - partikel dapat bermigrasi melintasi domain tugas yang membutuhkan lebih banyak pekerjaan untuk beberapa tugas. |

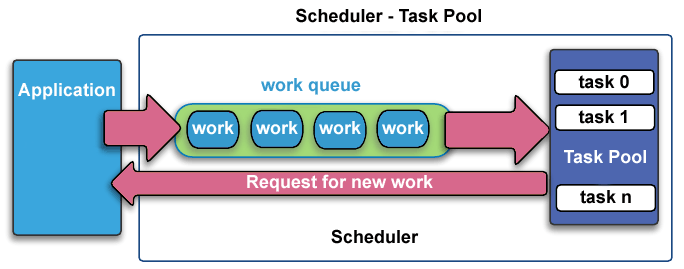
- Ketika jumlah pekerjaan yang akan dilakukan setiap tugas secara sengaja bervariasi, atau tidak dapat diprediksi, mungkin berguna untuk menggunakan pendekatan kumpulan tugas penjadwal . Saat setiap tugas menyelesaikan pekerjaannya, ia menerima bagian baru dari antrean pekerjaan.
schedulerTaskPool.gif
- Pada akhirnya, mungkin perlu untuk merancang algoritme yang mendeteksi dan menangani ketidakseimbangan beban saat terjadi secara dinamis di dalam kode.
Perincian
Rasio Komputasi / Komunikasi
- Dalam komputasi paralel, granularitas adalah ukuran kualitatif dari rasio komputasi terhadap komunikasi.
- Periode komputasi biasanya dipisahkan dari periode komunikasi oleh peristiwa sinkronisasi.
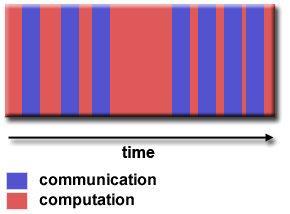
Paralelisme butir halus
perincian2.gif
- Jumlah pekerjaan komputasi yang relatif kecil dilakukan di antara peristiwa komunikasi.
- Rasio komputasi terhadap komunikasi yang rendah.
- Memfasilitasi load balancing.
- Menyiratkan overhead komunikasi yang tinggi dan lebih sedikit peluang untuk peningkatan kinerja.
- Jika perincian terlalu halus, kemungkinan overhead yang diperlukan untuk komunikasi dan sinkronisasi antar tugas membutuhkan waktu lebih lama daripada komputasi.
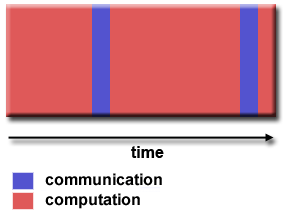
Paralelisme butiran kasar
perincian3.gif
- Jumlah pekerjaan komputasi yang relatif besar dilakukan antara peristiwa komunikasi / sinkronisasi
- Rasio komputasi terhadap komunikasi yang tinggi
- Menyiratkan lebih banyak peluang untuk peningkatan kinerja
- Lebih sulit memuat keseimbangan secara efisien
Mana yang Terbaik?
- Perincian yang paling efisien bergantung pada algoritme dan lingkungan perangkat keras tempatnya dijalankan.
- Dalam kebanyakan kasus, overhead yang terkait dengan komunikasi dan sinkronisasi relatif tinggi terhadap kecepatan eksekusi sehingga menguntungkan untuk memiliki perincian yang kasar.
- Paralelisme butiran halus dapat membantu mengurangi overhead akibat ketidakseimbangan beban.
I / O
Berita Buruk
memoryAccessTimes.gif
- Operasi I / O umumnya dianggap sebagai penghambat paralelisme.
- Operasi I / O membutuhkan lipat lebih banyak waktu daripada operasi memori.
- Sistem I / O paralel mungkin belum matang atau tidak tersedia untuk semua platform.
- Dalam lingkungan di mana semua tugas melihat ruang file yang sama, operasi tulis dapat mengakibatkan penimpaan file.
- Operasi baca dapat dipengaruhi oleh kemampuan server file untuk menangani beberapa permintaan baca secara bersamaan.
- I / O yang harus dilakukan melalui jaringan (NFS, non-lokal) dapat menyebabkan kemacetan parah dan bahkan server file crash.
Berita bagus
- Sistem file paralel tersedia. Sebagai contoh:
- GPFS: Sistem File Paralel Umum (IBM). Sekarang disebut Skala Spektrum IBM.
- Kilau: untuk cluster Linux (Intel)
- HDFS: Sistem File Terdistribusi Hadoop (Apache)
- PanFS: Panasas ActiveScale File System untuk cluster Linux (Panasas, Inc.)
- Dan banyak lagi - lihat http://en.wikipedia.org/wiki/List_of_file_systems#Distributed_parallel_file_systems
- Spesifikasi antarmuka pemrograman I / O paralel untuk MPI telah tersedia sejak tahun 1996 sebagai bagian dari MPI-2. Vendor dan penerapan "gratis" sekarang tersedia secara umum.
- Beberapa petunjuk:
- Aturan # 1: Kurangi keseluruhan I / O sebanyak mungkin.
- Jika Anda memiliki akses ke sistem file paralel, gunakan itu.
- Menulis potongan data yang besar daripada bagian kecil biasanya jauh lebih efisien.
- Lebih sedikit, file yang lebih besar berkinerja lebih baik daripada banyak file kecil.
- Batasi I / O ke bagian serial tertentu dari pekerjaan tersebut, lalu gunakan komunikasi paralel untuk mendistribusikan data ke tugas paralel. Misalnya, Tugas 1 dapat membaca file input dan kemudian mengkomunikasikan data yang diperlukan ke tugas lain. Demikian pula, Tugas 1 dapat melakukan operasi tulis setelah menerima data yang diperlukan dari semua tugas lainnya.
- Operasi I / O gabungan di seluruh tugas - daripada meminta banyak tugas melakukan I / O, minta subset tugas untuk melakukannya.
- GPFS: Sistem File Paralel Umum (IBM). Sekarang disebut Skala Spektrum IBM.
- Kilau: untuk cluster Linux (Intel)
- HDFS: Sistem File Terdistribusi Hadoop (Apache)
- PanFS: Panasas ActiveScale File System untuk cluster Linux (Panasas, Inc.)
- Dan banyak lagi - lihat http://en.wikipedia.org/wiki/List_of_file_systems#Distributed_parallel_file_systems
Debugging
- Men-debug kode paralel bisa sangat sulit, terutama karena skala kode meningkat.
- Kabar baiknya adalah ada beberapa debugger hebat yang tersedia untuk membantu:
- Berulir - pthreads dan OpenMP
- MPI
- GPU / akselerator
- Hibrida
- Pengguna Livermore Computing memiliki akses ke beberapa alat debugging paralel yang diinstal pada cluster LC:
- TotalView dari RogueWave Software
- DDT dari Allinea
- Inspektur dari Intel
- Stack Trace Analysis Tool (STAT) - dikembangkan secara lokal
- Semua alat ini memiliki kurva pembelajaran yang terkait dengannya - beberapa lebih dari yang lain.
- Untuk detail dan informasi memulai, lihat:
- Halaman web LC di https://hpc.llnl.gov/software/development-environment-software
- TotalView tutorial: https://computing.llnl.gov/tutorials/totalview/
- Berulir - pthreads dan OpenMP
- MPI
- GPU / akselerator
- Hibrida
- TotalView dari RogueWave Software
- DDT dari Allinea
- Inspektur dari Intel
- Stack Trace Analysis Tool (STAT) - dikembangkan secara lokal
- Halaman web LC di https://hpc.llnl.gov/software/development-environment-software
- TotalView tutorial: https://computing.llnl.gov/tutorials/totalview/
debug1.gif
Analisis Kinerja dan Tuning
- Seperti halnya debugging, menganalisis dan menyetel kinerja program paralel bisa jauh lebih menantang daripada untuk program serial.
- Untungnya, ada sejumlah alat yang sangat baik untuk analisis dan penyetelan kinerja program paralel.
- Pengguna Livermore Computing memiliki akses ke beberapa alat tersebut, yang sebagian besar tersedia di semua cluster produksi.
- Beberapa titik awal untuk alat yang dipasang pada sistem LC:
- Halaman web LC di https://hpc.llnl.gov/software/development-environment-software
- TAU: http://www.cs.uoregon.edu/research/tau/docs.php
- HPCToolkit: http://hpctoolkit.org/documentation.html
- Terbuka | Speedshop: https://www.openspeedshop.org/
- Vampir / Vampirtrace: http://vampir.eu/
- Valgrind: http://valgrind.org/
- PAPI: http://icl.cs.utk.edu/papi/
- mpiP: http://mpip.sourceforge.net/
- memP: http://memp.sourceforge.net/
- Halaman web LC di https://hpc.llnl.gov/software/development-environment-software
- TAU: http://www.cs.uoregon.edu/research/tau/docs.php
- HPCToolkit: http://hpctoolkit.org/documentation.html
- Terbuka | Speedshop: https://www.openspeedshop.org/
- Vampir / Vampirtrace: http://vampir.eu/
- Valgrind: http://valgrind.org/
- PAPI: http://icl.cs.utk.edu/papi/
- mpiP: http://mpip.sourceforge.net/
- memP: http://memp.sourceforge.net/
perfAnalysis.jpeg

Contoh Paralel
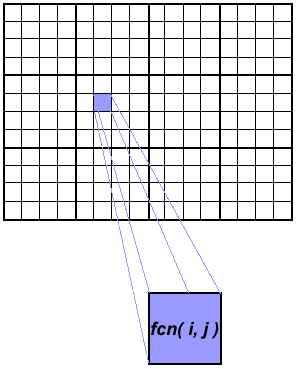
Pemrosesan Array
array_proc1.gif
- Contoh ini menunjukkan kalkulasi pada elemen array 2 dimensi; sebuah fungsi dievaluasi pada setiap elemen array.
- Perhitungan pada setiap elemen array tidak bergantung pada elemen array lainnya.
- Masalahnya intensif secara komputasi.
- Program serial menghitung satu elemen pada satu waktu secara berurutan.
- Kode serial bisa berupa:
do j = 1, n do i = 1, n a (i, j) = fcn (i, j) end do end do
- Pertanyaan untuk ditanyakan:
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
Solusi Paralel 1
array_proc2.gif
- Perhitungan elemen tidak bergantung satu sama lain - mengarah ke solusi paralel yang memalukan.
- Elemen array didistribusikan secara merata sehingga setiap proses memiliki bagian dari array (subarray).
- Skema distribusi dipilih untuk akses memori yang efisien; misalnya langkah unit (langkah 1) melalui subarray. Langkah unit memaksimalkan penggunaan cache / memori.
- Karena diinginkan untuk memiliki langkah unit melalui subarray, pilihan skema distribusi tergantung pada bahasa pemrograman. Lihat Block - Cyclic Distributions Diagram untuk opsinya.
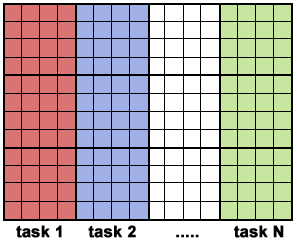
- Skema distribusi dipilih untuk akses memori yang efisien; misalnya langkah unit (langkah 1) melalui subarray. Langkah unit memaksimalkan penggunaan cache / memori.
- Karena diinginkan untuk memiliki langkah unit melalui subarray, pilihan skema distribusi tergantung pada bahasa pemrograman. Lihat Block - Cyclic Distributions Diagram untuk opsinya.
- Perhitungan independen elemen array memastikan tidak ada kebutuhan untuk komunikasi atau sinkronisasi antar tugas.
- Karena jumlah pekerjaan didistribusikan secara merata di seluruh proses, seharusnya tidak ada masalah keseimbangan beban.
- Setelah array didistribusikan, setiap tugas menjalankan bagian loop yang sesuai dengan data yang dimilikinya.
- Misalnya, distribusi blok Fortran (kolom-mayor) dan C (baris-mayor) ditampilkan:
Kolom-utama:
do j = mystart, myenddo i = 1, na (i, j) = fcn (i, j)end doend do
Baris-mayor:
untuk i (i = mystart ; i < myend ; i ++) {untuk j (j = 0; j <n; j ++) {a (i, j) = fcn (i, j);}}
- Perhatikan bahwa hanya variabel loop luar yang berbeda dari solusi serial.
SATU SOLUSI YANG MUNGKIN:
- Implementasikan sebagai model Single Program Multiple Data (SPMD) - setiap tugas menjalankan program yang sama.
- Proses master menginisialisasi array, mengirimkan info ke proses pekerja dan menerima hasil.
- Proses pekerja menerima info, melakukan bagian penghitungannya dan mengirimkan hasil ke master.
- Dengan menggunakan skema penyimpanan Fortran, lakukan distribusi blok dari array.
- Solusi kode semu: merah menyoroti perubahan paralelisme.
cari tahu apakah saya MASTER atau PEKERJA jika saya MASTER menginisialisasi larik kirim setiap info PEKERJA pada bagian larik yang dimilikinya kirim setiap PEKERJA bagiannya dari larik awal yang diterima dari setiap hasil PEKERJA lain jika saya PEKERJA menerima dari info MASTER pada bagian dari array yang saya terima dari MASTER bagian saya dari array awal # hitung bagian saya dari array do j = kolom pertama saya, kolom terakhir saya do i = 1, n a (i, j) = fcn (i, j) end do end do kirim hasil MASTER endif
PROGRAM CONTOH
Solusi Paralel 2: Kumpulan Tugas
- Solusi array sebelumnya mendemonstrasikan load balancing statis:
- Setiap tugas memiliki jumlah pekerjaan tetap yang harus dilakukan
- Mungkin waktu idle yang signifikan untuk prosesor yang lebih cepat atau lebih ringan - tugas paling lambat menentukan kinerja keseluruhan.
- Penyeimbangan beban statis biasanya tidak menjadi perhatian utama jika semua tugas melakukan jumlah pekerjaan yang sama pada mesin yang identik.
- Jika Anda mengalami masalah keseimbangan beban (beberapa tugas bekerja lebih cepat daripada yang lain), Anda dapat memanfaatkan skema "kumpulan tugas".
- Setiap tugas memiliki jumlah pekerjaan tetap yang harus dilakukan
- Mungkin waktu idle yang signifikan untuk prosesor yang lebih cepat atau lebih ringan - tugas paling lambat menentukan kinerja keseluruhan.
SKEMA POOL OF TASKS
- Dua proses digunakan
Proses Utama:
- Menyimpan kumpulan tugas untuk dilakukan oleh proses pekerja
- Mengirimkan tugas kepada pekerja saat diminta
- Mengumpulkan hasil dari pekerja
Proses Pekerja: melakukan hal berikut berulang kali
- Mendapat tugas dari proses master
- Melakukan komputasi
- Mengirimkan hasil ke master
- Proses pekerja tidak tahu sebelum runtime porsi array mana yang akan mereka tangani atau berapa banyak tugas yang akan mereka lakukan.
- Penyeimbangan beban dinamis terjadi pada waktu proses: semakin cepat tugas akan semakin banyak pekerjaan yang harus dilakukan.
- Solusi kode semu: merah menyoroti perubahan paralelisme.
cari tahu apakah saya MASTER atau PEKERJAjika saya MASTERlakukan sampai tidak ada pekerjaan lagijika permintaan kirim ke PEKERJA pekerjaan berikutnyalain terima hasil dari PEKERJAakhir lakukanlagi jika saya PEKERJAlakukan sampai tidak ada pekerjaan lagi yangmeminta pekerjaan dari MASTERterima dari MASTER pekerjaan berikutnyahitung elemen array: a (i, j) = fcn (i, j) kirim hasil ke MASTERend doendif
DISKUSI
- Dalam contoh kumpulan tugas di atas, setiap tugas menghitung elemen array individu sebagai pekerjaan. Rasio komputasi terhadap komunikasi sangat terperinci.
- Solusi yang sangat terperinci menimbulkan lebih banyak overhead komunikasi untuk mengurangi waktu idle tugas.
- Solusi yang lebih optimal mungkin dengan mendistribusikan lebih banyak pekerjaan dengan setiap pekerjaan. Jumlah pekerjaan yang "tepat" bergantung pada masalah.
Perhitungan PI
pi1.gif
- Nilai PI dapat dihitung dengan berbagai cara. Pertimbangkan metode Monte Carlo untuk mendekati PI:
- Tuliskan lingkaran dengan jari-jari r dalam bujur sangkar dengan panjang sisi 2 r
- Luas lingkaran adalah Πr2 dan luas persegi adalah 4r2
- Perbandingan luas lingkaran dengan luas persegi adalah:Πr2 / 4r2 = Π / 4
- Jika Anda secara acak menghasilkan N poin di dalam kotak, kira-kiraN * Π / 4 dari titik tersebut ( M ) harus berada di dalam lingkaran.
- Π kemudian didekati sebagai:N * Π / 4 = MΠ / 4 = M / NΠ = 4 * M / N
- Perhatikan bahwa meningkatkan jumlah poin yang dihasilkan meningkatkan perkiraannya.
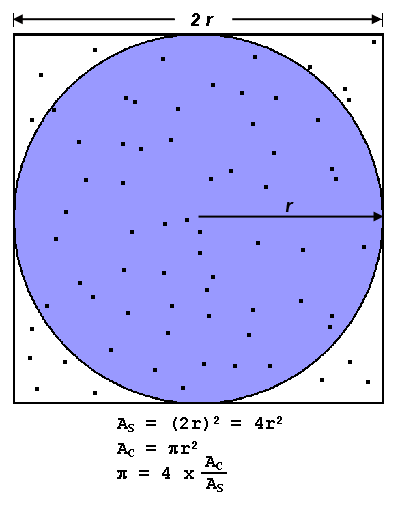
- Tuliskan lingkaran dengan jari-jari r dalam bujur sangkar dengan panjang sisi 2 r
- Luas lingkaran adalah Πr2 dan luas persegi adalah 4r2
- Perbandingan luas lingkaran dengan luas persegi adalah:Πr2 / 4r2 = Π / 4
- Jika Anda secara acak menghasilkan N poin di dalam kotak, kira-kiraN * Π / 4 dari titik tersebut ( M ) harus berada di dalam lingkaran.
- Π kemudian didekati sebagai:N * Π / 4 = MΠ / 4 = M / NΠ = 4 * M / N
- Perhatikan bahwa meningkatkan jumlah poin yang dihasilkan meningkatkan perkiraannya.
- Kode pseudo serial untuk prosedur ini:
npoints = 10000circle_count = 0do j = 1, npointsmenghasilkan 2 angka acak antara 0 dan 1xcoordinate = random1ycoordinate = random2jika (xcoordinate, ycoordinate) di dalam lingkaranmaka circle_count = circle_count + 1end doPI = 4.0 * circle_count / npoints
- Masalahnya intensif secara komputasi — sebagian besar waktu dihabiskan untuk menjalankan loop
- Pertanyaan untuk ditanyakan:
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
Solusi Paralel
pi2.gif
- Masalah lain yang mudah diparalelkan:
- Semua penghitungan poin bersifat independen; tidak ada ketergantungan data
- Pekerjaan bisa dibagi rata; tidak ada masalah keseimbangan beban
- Tidak perlu komunikasi atau sinkronisasi antar tugas
- Strategi paralel:
- Bagilah loop menjadi beberapa bagian yang sama yang dapat dijalankan oleh kumpulan tugas
- Setiap tugas melakukan tugasnya sendiri-sendiri
- Model SPMD digunakan
- Satu tugas bertindak sebagai master untuk mengumpulkan hasil dan menghitung nilai PI
- Semua penghitungan poin bersifat independen; tidak ada ketergantungan data
- Pekerjaan bisa dibagi rata; tidak ada masalah keseimbangan beban
- Tidak perlu komunikasi atau sinkronisasi antar tugas
- Bagilah loop menjadi beberapa bagian yang sama yang dapat dijalankan oleh kumpulan tugas
- Setiap tugas melakukan tugasnya sendiri-sendiri
- Model SPMD digunakan
- Satu tugas bertindak sebagai master untuk mengumpulkan hasil dan menghitung nilai PI
- Solusi kode semu: merah menyoroti perubahan paralelisme.
npoints = 10000circle_count = 0 p = number of tasknum = npoints / pcari tahu apakah saya MASTER atau WORKERdo j = 1, numgenerate 2 random number antara 0 and 1xcoordinate = random1ycoordinate = random2if (xcoordinate, ycoordinate) di dalam lingkaranmaka circle_count = circle_count + 1akhir lakukan jika saya MASTERmenerima dari PEKERJA circle_counts merekamenghitung PI (gunakan perhitungan MASTER dan PEKERJA)lain jika saya PEKERJAkirim ke MASTER circle_countendif
Program Contoh
Persamaan Panas Sederhana
heat_initial.gif
heat_equation.gif
- Sebagian besar masalah dalam komputasi paralel membutuhkan komunikasi antar tugas. Sejumlah masalah umum membutuhkan komunikasi dengan tugas "tetangga".
- Persamaan panas 2-D menjelaskan perubahan suhu dari waktu ke waktu, dengan mempertimbangkan distribusi suhu awal dan kondisi batas.
- Skema perbedaan hingga digunakan untuk menyelesaikan persamaan panas secara numerik pada daerah persegi.
- Elemen array 2 dimensi mewakili suhu pada titik-titik di persegi.
- Suhu awal nol di batas dan tinggi di tengah.
- Suhu batas dipertahankan pada nol.
- Algoritma loncatan waktu digunakan.
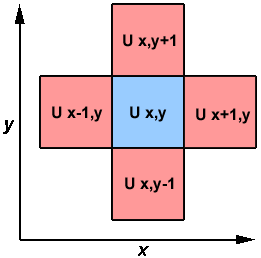
- Elemen array 2 dimensi mewakili suhu pada titik-titik di persegi.
- Suhu awal nol di batas dan tinggi di tengah.
- Suhu batas dipertahankan pada nol.
- Algoritma loncatan waktu digunakan.
- Perhitungan suatu elemen bergantung pada nilai elemen tetangga:
heat_equation2.gif
- Program serial akan berisi kode seperti:
do iy = 2, ny - 1 do ix = 2, nx - 1 u2 (ix, iy) = u1 (ix, iy) + cx * (u1 (ix + 1, iy) + u1 (ix-1, iy) - 2. * u1 (ix, iy)) + cy * (u1 (ix, iy + 1) + u1 (ix, iy-1) - 2. * u1 (ix, iy)) end do end do
- Pertanyaan untuk ditanyakan:
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
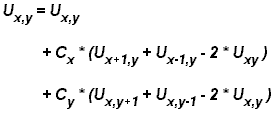
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
Solusi Paralel
heat_partitioned.gif
- Masalah ini lebih menantang, karena terdapat ketergantungan data, yang memerlukan komunikasi dan sinkronisasi.
- Seluruh larik dipartisi dan didistribusikan sebagai subarray ke semua tugas. Setiap tugas memiliki porsi yang sama dari total array.
- Karena jumlah pekerjaannya sama, penyeimbangan beban seharusnya tidak menjadi perhatian
- Tentukan ketergantungan data:
- elemen interior milik suatu tugas tidak bergantung pada tugas lain
- elemen perbatasan bergantung pada data tugas tetangga, yang membutuhkan komunikasi.
- Terapkan sebagai model SPMD:
- Proses master mengirimkan info awal ke pekerja, dan kemudian menunggu untuk mengumpulkan hasil dari semua pekerja
- Proses pekerja menghitung solusi dalam jumlah langkah waktu tertentu, berkomunikasi seperlunya dengan proses tetangga
- Solusi kode semu: merah menyoroti perubahan paralelisme.
cari tahu apakah saya MASTER atau PEKERJA
jika saya MASTER menginisialisasi array kirim setiap info awal PEKERJA dan subarray menerima hasil dari setiap PEKERJA
lain jika saya PEKERJA menerima dari MASTER memulai info dan subarray # Lakukan langkah waktu do t = 1, nsteps perbarui waktu kirim tetangga info perbatasan saya terima dari tetangga perbarui info perbatasan mereka bagian saya dari solusi array akhir mengirim hasil MASTER endif
- elemen interior milik suatu tugas tidak bergantung pada tugas lain
- elemen perbatasan bergantung pada data tugas tetangga, yang membutuhkan komunikasi.
- Proses master mengirimkan info awal ke pekerja, dan kemudian menunggu untuk mengumpulkan hasil dari semua pekerja
- Proses pekerja menghitung solusi dalam jumlah langkah waktu tertentu, berkomunikasi seperlunya dengan proses tetangga
Program Contoh
Persamaan Gelombang 1-D
- Dalam contoh ini, amplitudo di sepanjang string yang bergetar dan seragam dihitung setelah jangka waktu tertentu berlalu.
- Perhitungannya meliputi:
- amplitudo pada sumbu y
- i sebagai indeks posisi sepanjang sumbu x
- titik simpul dikenakan di sepanjang string
- pembaruan amplitudo pada langkah waktu diskrit.
- amplitudo pada sumbu y
- i sebagai indeks posisi sepanjang sumbu x
- titik simpul dikenakan di sepanjang string
- pembaruan amplitudo pada langkah waktu diskrit.
wave3.gif
- Persamaan yang harus diselesaikan adalah persamaan gelombang satu dimensi:
A (i, t + 1) = (2.0 * A (i, t)) - A (i, t-1) + (c * (A (i-1, t) - (2.0 * A (i, t) )) + A (i + 1, t)))
dimana c adalah sebuah konstanta
- Perhatikan bahwa amplitudo akan bergantung pada langkah waktu sebelumnya (t, t-1) dan titik sekitarnya (i-1, i + 1).
- Pertanyaan untuk ditanyakan:
- Apakah masalah ini bisa diparalelkan?
- Bagaimana masalah dipartisi?
- Apakah komunikasi dibutuhkan?
- Apakah ada ketergantungan data?
- Apakah ada kebutuhan sinkronisasi?
- Akankah teknik load balancing menjadi perhatian?
Solusi Paralel Persamaan Gelombang 1-D
- Ini adalah contoh lain dari masalah yang melibatkan ketergantungan data. Solusi paralel akan melibatkan komunikasi dan sinkronisasi.
- Seluruh array amplitudo dipartisi dan didistribusikan sebagai subarray untuk semua tugas. Setiap tugas memiliki porsi yang sama dari total array.
- Penyeimbangan beban: semua poin membutuhkan kerja yang sama, jadi poin harus dibagi rata
- Dekomposisi blok akan membuat pekerjaan dipartisi menjadi sejumlah tugas sebagai potongan, memungkinkan setiap tugas memiliki sebagian besar titik data yang berdekatan.
- Komunikasi hanya perlu terjadi di perbatasan data. Semakin besar ukuran blok, semakin sedikit komunikasinya.
wave4.gif
- Terapkan sebagai model SPMD:
- Proses master mengirimkan info awal ke pekerja, dan kemudian menunggu untuk mengumpulkan hasil dari semua pekerja
- Proses pekerja menghitung solusi dalam jumlah langkah waktu tertentu, berkomunikasi seperlunya dengan proses tetangga
- Solusi kode semu: merah menyoroti perubahan paralelisme.
cari tahu jumlah tugas dan identitas tugas
#Identifikasi tetangga kiri dan kanan left_ne Neighbor = mytaskid - 1 right_ne Neighbor = mytaskid +1 jika mytaskid = pertama lalu left_neigbor = terakhir jika mytaskid = terakhir lalu right_ne Neighbor = pertama-tama
cari tahu apakah saya MASTER atau PEKERJA jika saya am MASTER menginisialisasi larik kirim setiap info awal dan sub larik PEKERJA jika saya PEKERJA menerima info awal dan sub larik dari MASTER endif # Lakukan langkah waktu # Dalam contoh ini master berpartisipasi dalam perhitungan lakukan t = 1, nlangkah kirim titik akhir kiri ke tetangga kiri menerima titik akhir kiri dari tetangga kanan mengirim titik akhir kanan ke tetangga kanan menerima titik akhir kanan dari tetangga kiri # Perbarui poin di sepanjang garis do i = 1, npoints newval (i) = (2.0 * nilai (i)) - oldval (i) + (sqtau * (values (i-1) - (2.0 * values (i)) + values (i + 1))) end do
end do #Collect hasil dan tulis ke file jika saya MASTER menerima hasil dari setiap PEKERJA menulis hasil ke file lain jika saya PEKERJA kirim hasil ke MASTER endif
- Proses master mengirimkan info awal ke pekerja, dan kemudian menunggu untuk mengumpulkan hasil dari semua pekerja
- Proses pekerja menghitung solusi dalam jumlah langkah waktu tertentu, berkomunikasi seperlunya dengan proses tetangga
Program Contoh
Ini melengkapi tutorial.
Harap lengkapi formulir evaluasi online.
Referensi dan Informasi Lebih Lanjut
- Penulis: Blaise Barney, Livermore Computing (pensiun)
- Hubungi: hpc-tutorials@llnl.gov
- Pencarian di Web untuk "pemrograman paralel" atau "komputasi paralel" akan menghasilkan berbagai macam informasi.
- Bacaan yang direkomendasikan:
- "Merancang dan Membangun Program Paralel", Ian Foster - dari hari-hari awal komputasi paralel, tetapi masih mencerahkan.
- "Pengantar Komputasi Paralel", Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar.
- University of Orgegon - Kurikulum Komputasi Paralel Intel
- UC Berkeley CS267, Aplikasi Paralele Computing - https://sites.google.com/lbl.gov/cs267-spr2020
- Udacity CS344: Pengenalan Pemrograman Paralel - https://developer.nvidia.com/udacity-cs344-intro-parallel-programming
- Foto / Grafik telah dibuat oleh penulis, dibuat oleh karyawan LLNL lainnya, diperoleh dari sumber non-hak cipta, pemerintah atau domain publik (seperti http://commons.wikimedia.org/ ), atau digunakan dengan izin penulis dari presentasi dan halaman web lainnya.
- Sejarah: Bahan-bahan ini telah berkembang dari sumber-sumber berikut, yang tidak lagi dipelihara atau tersedia.
- Tutorial terletak di Maui High Performance Computing Center's "SP Parallel Programming Workshop".
- Tutorial yang dikembangkan oleh Cornell University Center for Advanced Computing (CAC), sekarang tersedia sebagai Workshop Virtual Cornell di: https://cvw.cac.cornell.edu/topics .
- "Merancang dan Membangun Program Paralel", Ian Foster - dari hari-hari awal komputasi paralel, tetapi masih mencerahkan.
- "Pengantar Komputasi Paralel", Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar.
- University of Orgegon - Kurikulum Komputasi Paralel Intel
- UC Berkeley CS267, Aplikasi Paralele Computing - https://sites.google.com/lbl.gov/cs267-spr2020
- Udacity CS344: Pengenalan Pemrograman Paralel - https://developer.nvidia.com/udacity-cs344-intro-parallel-programming
- Tutorial terletak di Maui High Performance Computing Center's "SP Parallel Programming Workshop".
- Tutorial yang dikembangkan oleh Cornell University Center for Advanced Computing (CAC), sekarang tersedia sebagai Workshop Virtual Cornell di: https://cvw.cac.cornell.edu/topics .

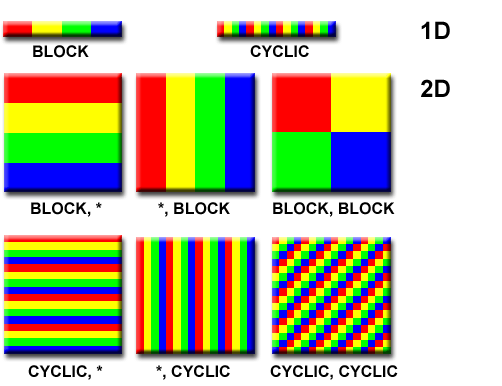{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment